

过去几十年里,计算机科学家不断推出更先进的人工智能(AI)系统,在特定任务上表现出色。其中,计算机视觉模型能够高速分析图像,用于分类、物体与人脸识别以及其他类型的精准预测。
然而,尽管这些视觉系统在多种任务上成绩亮眼,它们处理视觉信息的方式与人类仍有明显差异。人类更倾向于关注物体的整体形状和轮廓,而当前主流的AI视觉模型往往更依赖纹理特征,例如颜色变化、局部花纹或重复的视觉模式。这种偏好差异,被认为是AI视觉系统在某些场景下更容易出错的原因之一。
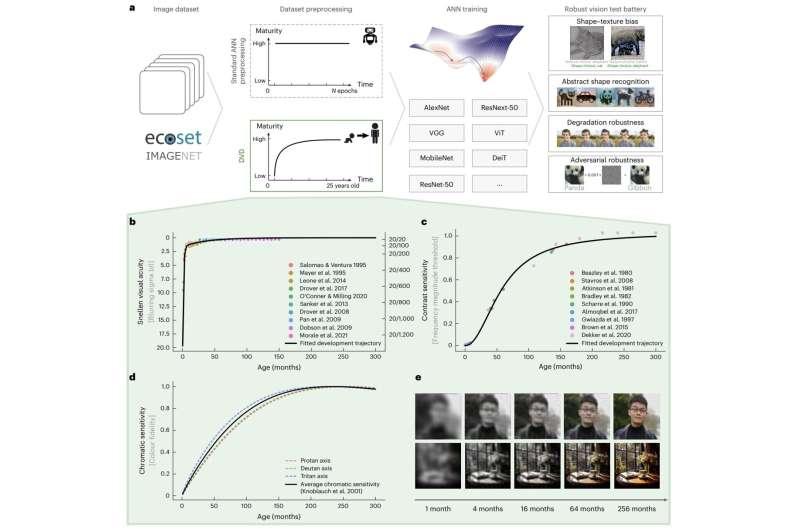
奥斯纳布吕克大学和柏林自由大学的研究人员近期提出了一种新的模型训练方法,灵感来自人类视觉系统的发育过程。他们将这一流程称为“发展视觉饮食”(developmental visual diet,DVD),相关成果发表在《自然机器智能》期刊上。
论文资深作者 Tim C. Kietzmann 在接受 Tech Xplore 采访时引用了加州大学伯克利分校 Alexei Efros 教授的一句话来概括当前问题:“我们正在培养一代算法,就像那些整个学期不去上课,只在期末前一晚临时抱佛脚的大学生;他们并没有真正学会内容,但考试成绩却不错。”
他指出:“我们确信深度神经网络鲁棒性差,与它们过度依赖纹理特征有关,而这似乎源自目前常用的训练设置。”
“发展视觉饮食”训练流程
为克服现有计算机视觉模型的这些局限,Kietzmann 及其团队尝试减少模型对纹理相关特征的依赖。他们最终提出了 DVD 流程,即一种模仿人类视觉发育过程的深度神经网络训练“课程”。

这一流程的核心思想是:让计算机视觉模型从“较粗糙”的视觉能力起步,随着训练逐步提升到高精度视觉表现,这与婴儿视觉能力随时间逐渐成熟的过程在概念上相似。
Kietzmann 介绍说:“博士生 Zejin Lu 深入梳理了大量关于视觉发育的研究文献,筛选出可能关键的因素。”
“他提出了三个候选因素:视觉敏锐度、对比敏感度和颜色。我们尽可能地模拟这三项能力随时间变化的轨迹。”
研究人员基于这一新流程训练深度神经网络,并在多种视觉处理任务上评估其表现,再与采用标准训练方法的模型进行对比。
结果显示,使用 DVD 训练的模型在决策时更依赖物体形状信息,而不是纹理特征。同时,这些模型在面对图像损坏以及对抗攻击(通过刻意修改图像来误导AI系统)时表现出更强的抵抗力。
Kietzmann 补充道:“它们在识别复杂场景中隐藏的符号或抽象形状方面也有更好表现——这类任务往往连最新的大规模AI模型也经常失败。”
初步成果与未来方向
研究团队提出的这一新流程未来有望进一步完善,并推广到更多类型的计算机视觉模型训练中。它可能帮助改进现有系统,或用于构建在特定物体检测、人脸识别以及生成具备特定视觉特征图像方面更为出色的新模型。
Kietzmann 表示:“我认为这一进展的重要性在于,它不仅给出了通往更依赖形状、同时更鲁棒的AI视觉系统的一条清晰路径,而且适用于在相对较少数据上训练的小型网络架构。”
“在‘规模化’常被视为解决AI问题万能钥匙的当下,这是一种令人耳目一新的小规模替代方案。由于 DVD 是一个预处理流程,对训练时间几乎没有额外开销,而推理阶段仍使用高分辨率图像,因此模型运行速度与原始模型基本相同。”
Kietzmann 及其同事的最新工作,可能会推动更多受人类发育过程启发的训练框架出现。与此同时,团队也计划继续开展研究,以进一步提升计算机视觉系统的整体性能。
他最后补充道:“我们目前正在探索其他受大脑和感官发育启发的概念,希望由此获得更鲁棒的AI视觉系统。同时,我们也在研究 DVD 相关发现对于将人工神经网络作为大脑功能模型这一方向意味着什么。”
© 2026 Science X Network









