

类脑计算与新型Bi2Se3忆阻器
随着人工智能算力需求逼近现有CMOS工艺的极限,模仿人脑结构与信息处理方式的类脑计算,被视为提升计算效率和能效的重要方向。在这一背景下,研究人员基于二维层状硒化铋(Bi2Se3)开发出一种新型忆阻器,兼具长期数据保持和连续模拟调节能力,可显著提升AI硬件的能效与处理速度。
这项工作由密歇根大学工程学院团队完成,并发表在《ACS Nano》期刊上。
同时满足三项关键性能指标
Bi2Se3忆阻器在同一器件中实现了此前实用忆阻器难以同时具备的三项关键技术要求:
- 长期数据保持(非易失性):写入信息后可长时间稳定保存;
- 模拟式存储状态:电导可连续可调,而非简单的“开/关”二值切换;
- 无需外部电流调节器即可在电路中稳定运行。
在演示实验中,该忆阻器被用作一个全模拟、全硬件储备计算网络中的核心器件,用于控制一个平衡杆系统,并成功完成任务。

密歇根大学机械工程教授、论文通讯作者梁晓刚表示,这一成果为构建硬件神经网络的关键元件提供了新的实现路径,使忆阻器能够以更符合AI电路设计需求的方式工作。
可扩展的Bi2Se3忆阻器交叉阵列
忆阻器是一类其电阻会随历史电流或电压变化而改变的器件,是实现“存内计算”和类脑计算的重要基础。通过在同一器件中同时进行存储与计算,可减少传统架构中数据在存储单元与处理单元之间频繁传输带来的瓶颈。
然而,用于硬件神经网络的忆阻器往往存在性能取舍:
- 具备良好非易失性的数据长期保持器件,通常需要外部电流调节电路以避免突变开关;
- 具备优良模拟调节能力的器件,则往往在数据保持方面表现不足。
为解决这一矛盾,研究团队在硅基底上制备了垂直堆叠的Bi2Se3忆阻器交叉阵列。具体工艺包括:
- 在厚度约300纳米的二氧化硅层上,通过光刻制备宽约500纳米的金(Au)底电极;
- 采用物理气相沉积方法,在金电极上直接生长由少层二维片层堆叠而成的Bi2Se3薄片;
- 金既作为底电极,又用于调控Bi2Se3的成核位置和晶粒尺寸,从而在预定区域实现可控生长;
- 随后在垂直方向沉积钛(Ti)和额外的金层,在交叉点形成Au/Bi2Se3/Ti的垂直夹层结构。
这种基于金辅助的气相沉积工艺与现有半导体制造流程兼容,具备良好的可扩展性,有利于未来大规模集成。
金丝状导电结构带来的精细模拟调节
在器件性能测试中,Bi2Se3忆阻器展现出:
- 约10–40%的强模拟电导调节范围;
- 在约10000秒时间尺度内,数据保持损失小于1%;
- 在工作过程中无需额外的外部电流调节器。
元素分析与数值模拟结果表明,当施加电压时,细小的指状金丝会从底电极向Bi2Se3层内部延伸。这些导电金丝在不与顶电极直接连通的前提下发生生长与收缩,从而实现电导的平滑、连续调节。
交叉阵列形成的晶格结构为这些金丝的动态演化提供了空间,使器件电阻可以被持续、可控地调节,进而支持高效的存内计算过程。

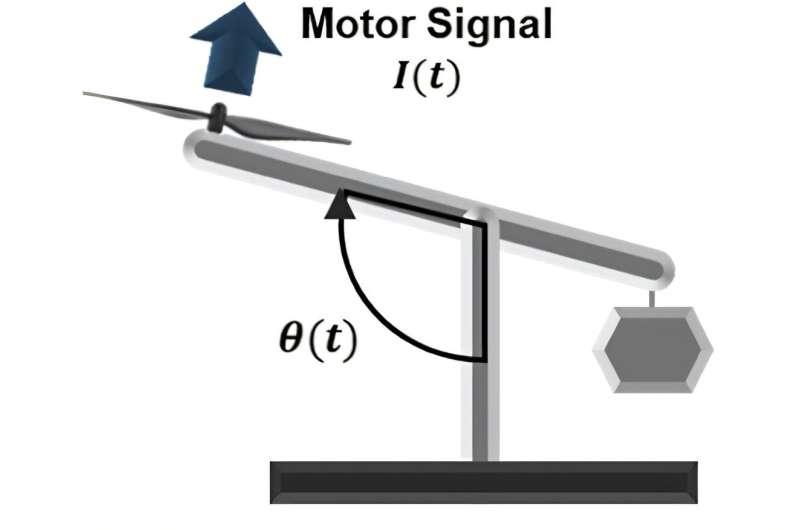
全模拟硬件储备计算:平衡杆控制实验
为验证器件在实际类脑计算任务中的可用性,研究团队将Bi2Se3忆阻器集成进一个全模拟、全硬件的储备计算网络,用于控制一个平衡杆系统。
该平衡杆装置类似跷跷板结构:
- 一端安装电机与螺旋桨;
- 另一端悬挂重物;
- 系统配备传感器实时检测杆的倾斜角度。
控制目标是通过调节螺旋桨的转动力度,使平衡杆动态调整并稳定在90度角位置。
在这一系统中,Bi2Se3忆阻器取代了传统储备计算中通常由软件实现的读出层,直接在硬件中完成对螺旋桨驱动力度的计算与输出。由于整个过程保持在模拟域内,无需模拟-数字转换,系统功耗被压缩到约7微瓦(7×10⁻⁶瓦)的水平。相比之下,普通家用LED灯的功率通常在8–12瓦左右,两者能耗相差数个数量级。
面向高能效类脑AI硬件的潜力
如果这一Bi2Se3忆阻器技术能够实现大规模集成与量产,有望:
- 推动新一代类脑计算芯片与系统的开发;
- 显著提升AI硬件在能效和处理速度方面的表现;
- 简化电路设计,减少对复杂外围调节电路的依赖。
总体来看,这种兼具长期数据保持、模拟调节能力且无需外部调节器的Bi2Se3忆阻器,为构建高能效、全模拟的硬件神经网络提供了一个具有现实可行性的器件方案。









