

富士通于2026年6月24日宣布,成功开发出一种面向大规模语言模型(LLM)推理成本削减的新型架构——Parallel Hierarchical Operation for TOp-down Networks(PHOTON)。
与当前主流的 Transformer 架构相比,PHOTON 在多路查询(Multi-Query)场景下的性能可实现最高约 475 倍的提升。这里的“多路查询性能”指的是单位 GPU 资源所能处理的并行输出数量(吞吐量),并不意味着模型本身的精度或单次推理性能提升 475 倍,而是强调:在相同 GPU 资源下,可以同时生成更多结果,从而显著降低推理成本。
Transformer 在长文本与并发场景中的瓶颈
随着生成式 AI 的应用不断扩展,LLM 需要同时满足两类高负载需求:
- 处理更长的文档、上下文和对话历史;
- 同时响应大量用户的并发请求。
此外,通过在推理时“让模型思考更久”(例如更长的推理链、更丰富的候选生成)来提升回答质量的做法也日益普及,这进一步推高了计算与内存资源的压力。
在传统 Transformer 中,文本会被拆分为细粒度的token(标记),模型需要在每一步生成时,基于过去的全部 token 计算注意力。随着输入长度增加或并发请求增多:
- 为保留历史信息,需要频繁读写 KV cache(键值缓存);
- 内存访问次数和带宽占用急剧上升;
- 推理速度容易因内存带宽成为瓶颈而明显下降。
富士通认为,这种瓶颈在长文本处理和大规模并发使用场景中尤为突出,直接制约了 LLM 的服务能力与成本结构。
PHOTON 的设计目标,就是在多智能体、多输入输出等需要大量并行生成的场景下,用更少的 GPU 资源支撑更多请求,从而提升推理效率、降低 GPU 成本。
从“按 token 扫描”到“按语义分层”:PHOTON 的核心思路
PHOTON 与传统 Transformer 的最大差异,在于其对文本的处理方式:
- Transformer:以 token 为基本单位,沿时间轴“平面式”逐步扫描和计算;
- PHOTON:将文本视为若干语义单元的层级结构,进行分层、分辨率不同的处理。
在常规 Transformer 中,每生成一个新 token,都需要访问此前全部 token 的 KV cache。虽然这种机制保证了较高的建模能力,但在长序列或多路查询时:
- KV cache 规模迅速膨胀;
- 读写频率极高,内存带宽成为主要瓶颈。
PHOTON 则采用了不同的策略:
-
分层压缩输入:
- 将输入 token 逐步压缩为更高层次的语义表示;
- 以较低更新频率的“文脉状态(上下文状态)”形式进行保存。
-
自顶向下轻量解码:
- 使用轻量级的自顶向下解码器(top-down decoder),从高层语义状态中重建细粒度的 token 表示;
- 在生成过程中,更多依赖紧凑的分层语义状态,而非完整的 token 级 KV cache。
根据富士通在 arXiv 公开的论文,PHOTON 可被视为一种分层自回归模型:
- 将传统“水平方向、逐 token 扫描”的访问模式;
- 替换为“垂直方向、多分辨率的上下文访问”。
通过这种结构,PHOTON 在推理时显著减少了对大规模 KV cache 的依赖,从根本上缓解了内存访问和带宽压力。
1.2B 参数模型上实现约 475 倍多路查询吞吐提升
富士通在 600M、900M、1.2B 三种参数规模的模型上进行了数值实验,对比 PHOTON 与传统 Transformer 在内存占用和生成吞吐方面的表现。
实验结果显示:
- 在相同硬件条件下,PHOTON 能在更低内存使用量下,提供更高的生成吞吐量;
- 尤其是在多路并发生成场景中优势明显。
在 1.2B 参数规模的模型上,PHOTON 在允许轻微性能下降的前提下:
- 相比传统 Transformer,实现了约 475 倍的多路查询计算能力提升;
- 关键原因在于:PHOTON 每次生成所需的 KV cache 规模更小,使得在同一 GPU 显存预算内,可以并行运行更多条生成任务。
换言之,在相同 GPU 资源下:
- 传统 Transformer 可能一次只能服务少量请求;
- PHOTON 则能同时跑数百倍数量级的并行生成,大幅提升服务能力并摊薄成本。
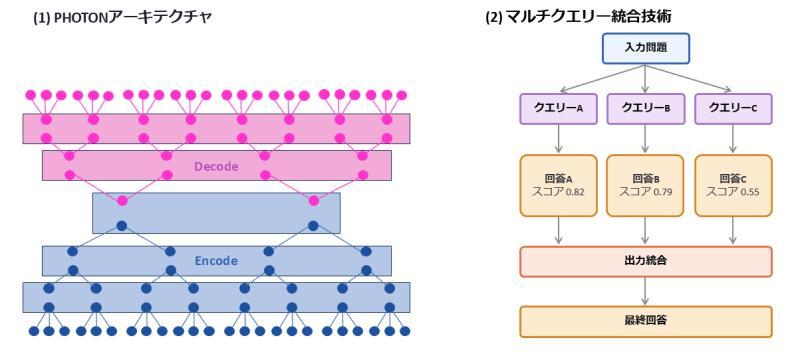
通过“多路查询结果整合”弥补精度损失
在提升吞吐的同时,富士通还提出了多路查询整合技术,用于在不显著增加单次推理成本的前提下,提升最终答案质量。
其基本思路是:
- 针对同一个问题,构造若干略有差异的提问方式或候选生成;
- 使用 PHOTON 并行生成多个回答;
- 通过一定的整合策略,将这些回答进行融合,得到更高置信度的最终结果。
在验证实验中,富士通发现:
- 当对 9 条查询结果进行整合时,PHOTON 的整体性能可以达到与传统 Transformer 大致相同的水平;
- 同时仍然保留了 PHOTON 在多路并行吞吐上的巨大优势。
这意味着,在实际应用中可以通过“多样化提问 + 结果整合”的方式,在不牺牲成本优势的前提下,维持甚至提升模型的回答质量。
将在 ACL 2026 口头报告,目标是全面降低 LLM 运行成本
PHOTON 相关成果计划在 2026 年 7 月 2 日起于美国圣迭戈举行的自然语言处理国际会议 The 64th Annual Meeting of the Association for Computational Linguistics(ACL 2026) 上,以口头报告(Oral)形式进行发布。
富士通表示,未来将围绕 PHOTON 等新一代架构,持续推进生成式 AI 技术的高效化与轻量化,重点方向包括:
- 提升 GPU 资源利用效率;
- 降低推理过程中的功耗;
- 全面压缩大模型的运营与维护成本。
通过在架构层面突破 Transformer 的内存与带宽瓶颈,富士通希望为大规模部署 LLM 提供更具成本优势的技术路径。









