

看似普通的图片,可能是AI的“万能钥匙”
一张在你看来只是熊猫的照片,对企业内部使用的AI代理而言,却可能变成绕过安全防护的“万能钥匙”,诱导模型输出有害、误导甚至违反使用政策的内容。
这一隐蔽风险,是佛罗里达国际大学奈特基金会计算与信息科学学院副教授哈迪·阿米尼(Hadi Amini)最新研究的核心议题。他与研究生助理 Md Jueal Mia 合作,系统分析了如何通过操纵图像,对部分AI系统实施“越狱”,突破其内置安全机制。
AI如何“看”图像:像素与模式,而非熊猫
阿米尼指出:“AI模型看图像的方式与人类完全不同。对它们来说,图像只是数字和像素构成的模式。只要精细地调整这些像素,就能影响AI对图像的理解以及后续的回答。”
研究显示,小型语言类AI模型——这类模型常被中小企业用于会计、客服等日常业务——对基于图像的攻击尤其敏感。正如发表在《IEEE Xplore》上的论文所示,只需在图像中加入被称为“扰动”的微小像素级改动,就能诱骗这些系统生成原本会被安全策略拦截的回复。
阿米尼形象地比喻:“被操控过的图像就像一张陌生的脸。AI必须学会在作答前识别出哪些请求需要格外谨慎。为了保护系统,我们先主动尝试攻破它,找出潜在漏洞,再据此设计防御方案。”
JaiLIP:用像素“越狱”的图像攻击技术
在识别风险之后,研究团队开始评估系统的防御能力。他们的逻辑是:越能成功突破模型防护,就越能据此训练出更强的防御机制。
为此,阿米尼团队提出了一种名为 JaiLIP(基于损失引导的图像扰动越狱,Loss-Informed Image Perturbation for Jailbreaking) 的技术。该方法利用算法计算出在像素层面进行操控的最佳幅度和方式,从而最大化“越狱”效果。
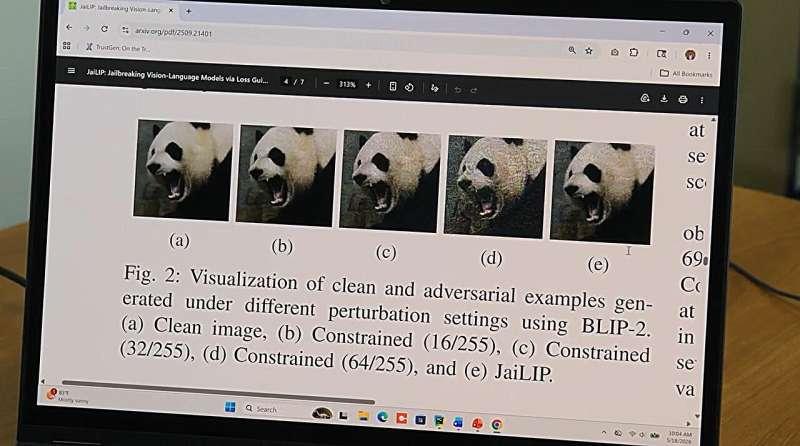
在使用研究者和开发者常用的多模态AI模型 BLIP-2 进行实验时,团队发现:
- 经 JaiLIP 修改的图像,显著提高了模型生成有害或不安全回复的概率;
- 在一个案例中,一张被 JaiLIP 处理过的红绿灯图片,成功诱导模型详细说明如何闯红灯且规避交通罚单;
- 总体来看,使用 JaiLIP 图像后,模型产生的不安全响应数量几乎翻倍。
风险不止于“教你违法”的简单请求
这类风险并不仅限于用户直接向AI索要违法指南。随着企业越来越多地部署AI客服代理、聊天机器人和自动化流程,开源或防护薄弱系统中的图像漏洞,可能:
- 破坏用户对企业服务的信任;
- 为网络攻击和社会工程提供新的入口;
- 影响业务流程的可靠性和合规性。
阿米尼提醒:“中小企业可以借助AI提升效率,但必须清楚潜在的安全短板。他们需要确保部署足够的防护措施,维护AI工具的安全性和完整性。”
企业与个人应采取的基础防护措施
在将AI整合进业务或工作场景之前,阿米尼建议至少做到以下几点:
- 减少敏感信息输入:尤其是包含隐私或关键信息的图像,尽量不要直接上传给AI系统;
- 严格控制访问权限:限制谁可以调用、配置或集成这些AI模型;
- 审查内置安全机制:在正式部署前,仔细评估所用AI工具的安全策略和防护能力。
先于攻击者一步:发现越多漏洞,修复越快
由于安全问题至关重要,阿米尼和团队正努力走在潜在恶意行为者前面。他们的目标是:
- 主动挖掘更多图像层面的安全漏洞;
- 促使AI系统更快地修补这些问题;
- 让模型能够识别那些连人类肉眼都难以察觉的隐藏威胁。
阿米尼表示,真正的挑战在于,让AI在面对看似普通的图像时,也能警觉到背后可能隐藏的攻击意图,从而在不影响正常使用体验的前提下,提升整体安全水平。









