
一种新方法被提出,用来应对人工智能(AI)的“过度自信”问题——这是自动驾驶、医疗诊断等高风险场景中最关键的安全隐患之一。在这些应用里,AI往往会对明显错误的预测依然给出极高的置信度。韩国科学技术院(KAIST)研究团队开发出一套新的训练策略,让AI能够识别何时遇到不熟悉或从未见过的知识情形,从而为降低过度自信、提升系统可靠性打下基础。
精确追踪过度自信的源头
该研究由脑与认知科学系杰出教授白世范(Se-Bum Paik)领衔。团队发现,深度学习中普遍采用的“随机初始化”技术,很可能是AI过度自信的根本来源之一。深度学习依靠人工神经网络从数据中学习,而在训练开始前,网络权重通常会被随机设定。
研究人员提出了一种新的“预热”策略:在用真实数据训练之前,先用随机噪声(即无意义的任意输入)对神经网络进行短暂训练。相关成果已发表在《自然机器智能》(Nature Machine Intelligence)期刊上。
实验显示,AI的过度自信在初始化阶段就已经出现,并在后续训练中被放大,最终导致严重错误。当随机数据输入到随机初始化的神经网络时,即便模型尚未真正学到任何东西,它依然会给出置信度很高的输出。这种特性被认为与生成式AI的“幻觉”现象密切相关——模型会以极具说服力的方式生成错误信息。

为寻找解决思路,研究团队从生物大脑中获得启发。人类大脑在出生前就会通过“自发神经活动”(无需外部刺激即可产生的脑信号)来塑造神经回路结构。
借鉴大脑发育的“预热”思路
研究人员将这一理念迁移到人工神经网络中,引入“预热阶段”:在正式学习真实数据之前,先用随机噪声对网络进行短暂预训练。可以理解为,AI在真正开始学习世界之前,先对自身的不确定性进行一次“校准”。
经过预热后,模型的初始置信度被压低到接近随机水平,显著削弱了传统随机初始化所带来的过度自信偏差。
换句话说,在接触真实数据前,模型先学会了一种“我还一无所知”的状态。随后,当它再去学习真实数据时,预测的准确率(答对的频率)与置信度(自认为有多对)会更加自然地对齐。
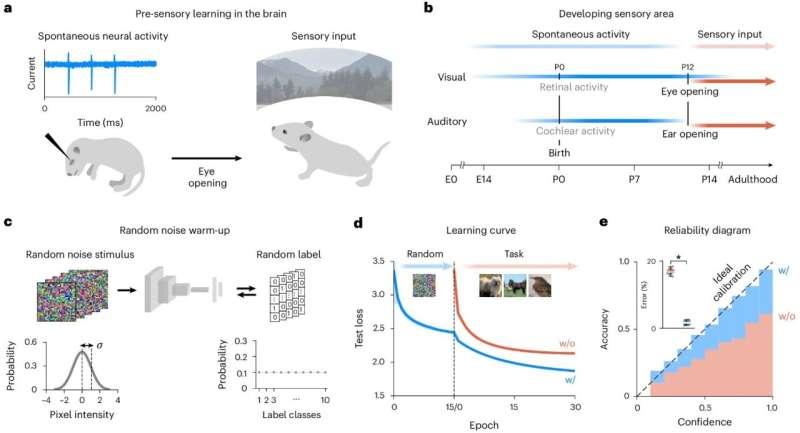
在面对未见过的数据时,这种差异尤为明显。传统模型即使遇到训练中从未出现的样本,也往往会给出置信度很高但完全错误的答案;而经过预热训练的模型,则更倾向于降低置信度,更好地识别出“我不知道”的情形。
迈向更安全、更可靠的AI
这种训练方式在“分布外检测”(识别与训练数据分布明显不同的输入)任务上也展现出强劲表现。模型不仅更容易察觉异常输入,还能在不确定时主动收缩自信,而不是盲目给出肯定回答。
研究结果表明,AI有可能从单纯追求“答对多少题”,进化到具备区分“自己知道什么”和“自己不知道什么”的能力。这种对自身认知状态的觉察,被称为元认知。
白世范教授指出:“我们的研究显示,只要把大脑发育中的关键原理融入训练过程,AI就能以更接近人类的方式识别自己的知识边界。”他补充说:“这不仅是为了提高正确回答的比例,更重要的是让AI在不确定或可能出错时能够意识到这一点。”
研究团队预计,这项技术不仅适用于自动驾驶、医疗AI和生成式AI等对可靠性要求极高的领域,也有望推广到几乎所有依赖深度学习的模型初始化过程中,成为提升整体AI安全性与可信度的一项关键基础技术。










