

斯坦福大学人本人工智能研究院(HAI)于 2026 年 4 月 4 日正式发布《AI Index Report 2026》。报告显示,全球顶尖 AI 模型的整体性能仍在快速提升,但不同国家与企业之间的性能差距正在迅速缩小。尤其是美国与中国之间的模型性能差,到 2026 年时已被压缩至仅 2.7%。
美中 AI 模型性能差距几乎消失
根据《AI Index 2026》,过去数年间,美中两国 AI 模型的性能差距明显收窄。
在 2023 年,美国模型在多项基准测试上仍保持明显领先。但从 2024 年到 2025 年,这一差距急剧缩小:到 2025 年 2 月,中国的 DeepSeek-R1 模型在综合评分上与美国顶级模型之间的差距已缩小到仅 0.4%。
进入 2026 年,差距进一步被压缩。到 2026 年 3 月,美国顶级模型 Claude Opus 4.6 仅以 39 个评分点(约 2.7%)的优势领先中国顶级模型。
报告指出,在过去一年中,美中模型之间的性能差基本稳定在个位数百分比区间,两国在前沿 AI 能力上的竞争已进入“几乎势均力敌”的阶段。
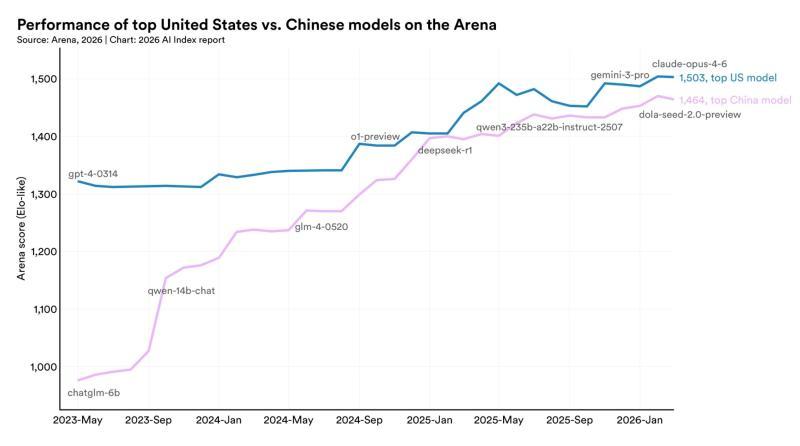
头部模型进入“横向齐平”阶段
不仅在国家层面,企业之间的性能差也在快速缩小。
截至 2026 年,Anthropic、xAI、Google、OpenAI 等主要厂商推出的旗舰模型,在主流基准测试中的得分高度集中在同一档位。报告显示,排名前四的模型之间分数差距不足 25 个评分点,整体呈现出事实上的“横向齐平”状态。
这意味着,过去那种简单以“谁的模型最强”来做线性排序的方式,已经越来越难以反映真实差异。模型之间的领先优势变得更细微,也更依赖具体场景和任务类型。
竞争焦点从“性能”转向“实用性”
随着模型在综合性能上的差距不断缩小,AI 竞争的核心维度正在发生转移。《AI Index 2026》认为,未来的竞争优势将更多体现在以下几个方面:
- 成本(包括推理成本与部署成本)
- 延迟(响应速度与交互流畅度)
- 可靠性(稳定性、安全性与一致性)
- 针对特定行业或任务的定制化与优化能力
换言之,单纯在通用基准上“跑分更高”不再是决定性因素,“能否真正高效、稳定地服务于实际业务场景”将成为新的关键分水岭。
多项基准上已超越人类水平
在能力层面,当前顶级 AI 模型已经在多项经典基准上超越了人类平均水平。
在 ImageNet、SuperGLUE、MMLU 等长期使用的评测数据集上,最新模型的表现已超过人类基准。此外,在博士级科学问题(GPQA)以及多模态推理(MMMU)等更高难度任务上,模型性能也在近年实现了大幅跃升。

然而,报告同时强调,在涉及真实世界环境的复杂任务上,AI 仍存在明显短板。例如:
- 复杂软件系统的开发与维护
- 需要与物理世界交互的操作类任务
- 长周期、多步骤、强约束的现实业务流程
在这些领域,AI 与人类专家之间仍存在不小差距。
AI 基准测试与人类表现对比
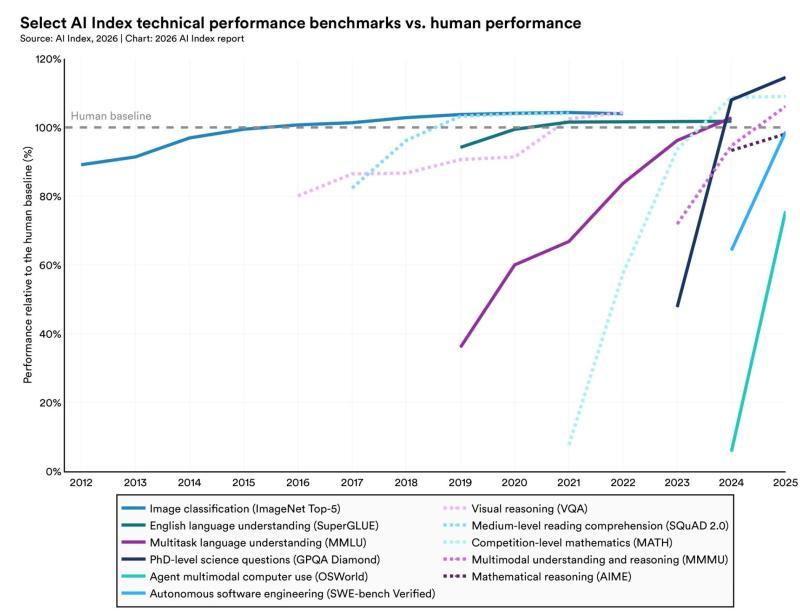
报告还指出,AI 能力的快速演进正在反过来暴露现有评测体系的局限性:
- 许多主流基准在短时间内就被“打满分”,难以继续区分顶级模型之间的细微差异;
- 部分评测方法本身存在较大误差,在某些任务上测得的结果误差最高可达 42%,对模型真实能力的刻画并不充分。
这意味着,如何构建更科学、更可靠的新一代评测体系,已成为 AI 研究与产业界共同面临的新课题。
AI 竞争进入新阶段:基础设施与落地能力成关键
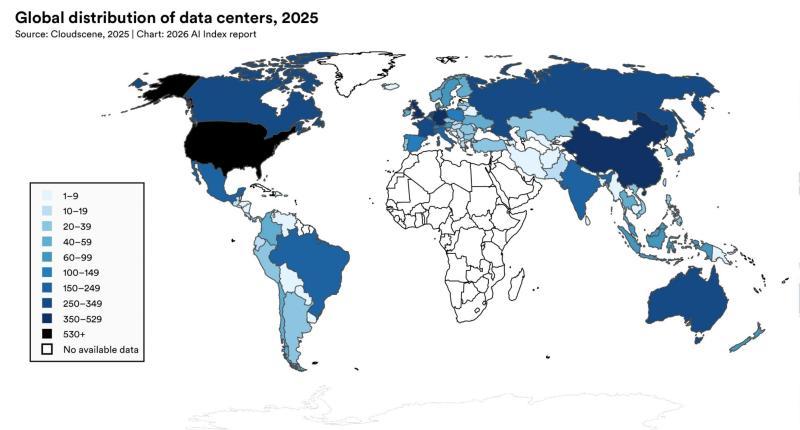
《AI Index 2026》一方面展示了美中在模型性能上的差距大幅缩小,另一方面也指出,在基础设施层面,美国仍保持明显领先。
尤其是在数据中心等算力基础设施方面,美国目前拥有的 AI 数据中心数量远超其他国家,为大规模模型训练与部署提供了更充足的资源保障。
在模型性能逐渐“拉平”的背景下,报告认为,未来竞争的关键将更多集中在:
- 算力与数据中心等基础设施的规模与布局
- 成本控制与能效优化能力
- 面向不同行业、不同场景的解决方案与生态构建
- 服务质量、可靠性与合规性
全球数据中心分布概况
总体来看,《AI Index 2026》勾勒出这样一幅图景:
- 顶级模型在“能力天花板”上仍在持续抬升;
- 美中以及主要厂商之间的性能差距却在快速缩小;
- 竞争重心正从“谁更强”转向“谁更好用、更便宜、更稳定、更贴近业务场景”。
AI 产业正在从单点性能竞赛,迈入以综合实力和实际落地效果为核心的新阶段。









