

通常,AI要想理解复杂的人类动作,需要大量标注完善的训练视频数据。但在真实应用中,针对某些特定动作往往难以收集到足够多的样本。由成均馆大学软件系许在弼教授带领的研究团队提出了一项新技术,只需少量示例视频,就能让AI准确识别此前未见过的新动作。
该团队聚焦于“少样本动作识别”问题,目标是让AI在样本极少的条件下,也能学习并区分不同动作的关键特征。与传统方法依赖对整段视频逐帧、按时间顺序进行复杂比对不同,这项技术的核心思路是:从视频中高效提炼出关键动作片段,再基于这些精炼信息进行视频间的比较。
为实现这一点,研究人员从多个角度对每个视频进行分析,提取并组织其中具有代表性的动作模式。通过这种方式,AI不再被冗长的时间序列所束缚,而是能够围绕“动作本质”进行对比,从而更有效地判断不同视频之间的相似与差异。
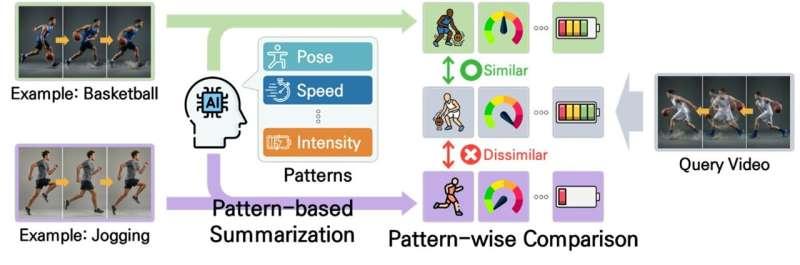
该方法的一大亮点在于对动作速度和持续时间变化的鲁棒性。即便同一动作因个人习惯、拍摄角度或环境条件不同而以快慢不一、时长不同的形式出现,算法仍能抓住动作的核心结构特征,稳定完成识别,显著减弱了时间尺度变化带来的干扰。
凭借在方法上的创新性和性能上的优异表现,这项研究已获得国际学术界的认可。相关论文被选为将在2025年6月于纳什维尔举办的计算机视觉与模式识别会议(CVPR 2025)口头报告,并收录于《2025 IEEE/CVF计算机视觉与模式识别会议(CVPR)》期刊。
研究团队表示,这项技术有望在多种需要高级视频理解能力的场景中发挥作用,例如体育动作分析与训练反馈、用于识别危险行为的智能安防系统,以及帮助机器人通过观察人类示范来自主学习新行为等应用领域。
发表评论
登录后才可评论。
去登录









