

随着数字内容在网络上的高速传播,被篡改的视频在媒体报道、安全监控以及司法取证等领域带来的风险不断增加。近期发表在《工程研究杂志》上的一项研究,提出了一种自动检测视频插帧篡改的新方法。这里的“插帧”指的是人为向视频序列中加入图像,以平滑篡改痕迹,使视频看起来更自然、更真实。
研究团队设计了一个由三阶段组成的检测流程,将传统图像处理技术与深度学习模型相结合。
第一阶段中,系统首先将输入视频拆分为单独的帧。每一帧都会被统一调整为 256×256 像素,并通过滤波操作降低噪声干扰,为后续分析提供更干净的图像数据。
第二阶段,研究人员利用双线性插值生成合成帧。通过这些合成数据,系统可以更好地学习插帧篡改在视觉上的行为特征,从而区分正常帧与被人为插入的帧。
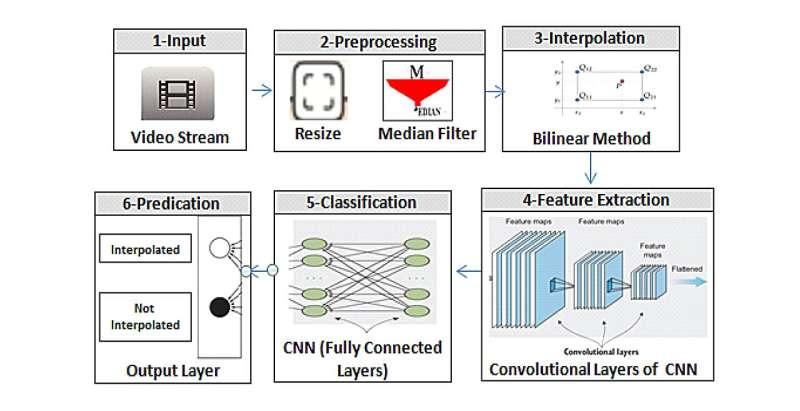
在第三阶段,卷积神经网络(CNN)对每一帧进行分析。CNN会自动从像素级数据中提取视觉特征,并将帧分类为“原始”或“篡改”。与依赖人工设计特征的传统方法不同,CNN能够直接从数据中学习有用特征,减少了特征工程的工作量,也提升了对细微篡改痕迹的敏感度。
该系统在广泛使用的 UCF101 数据集上进行了测试。UCF101 包含 101 个类别、超过 13000 段视频片段。实验结果显示,该方法在该数据集上的检测准确率约为 95%。在相同条件下进行对比实验时,支持向量机(SVM)模型的准确率仅为 70%,这突显了深度学习方法在识别细微视觉篡改方面的明显优势。
研究人员还强调,这一方法不仅能够判断视频中是否存在篡改帧,还可以精确标出这些帧在视频流中的具体位置。这一能力使其在数字取证、内容验证以及相关安全应用中具有更高的实用价值。
发表评论
登录后才可评论。
去登录









