

加州大学河滨分校的一项新研究,通过让人工智能系统以更接近人类的方式进行推理,为解决人工智能领域的一大难题提供了实用路径——在除测试问题本身外,不需要任何额外训练数据。
这项工作发表于 arXiv 预印本平台,论文题为《测试时匹配:解锁多模态模型中的组合推理》(Test-Time Matching: Unlocking Compositional Reasoning in Multimodal Models)。论文作者、伯恩斯工程学院电气与计算机工程系助理教授朱英伦及其学生提出了一种名为“测试时匹配”(Test-Time Matching,TTM)的新方法。该方法显著增强了人工智能系统理解文本与图像之间关系的能力,尤其是在面对从未见过的新组合时。
朱英伦解释说:“组合推理关注的是像人类那样进行泛化,用已知的部分去理解全新的组合。这是让人工智能真正理解世界,而不仅仅是记忆模式的关键。”
目前的主流人工智能模型在许多任务上表现优异,但在“组合压力”下对齐视觉场景和语言描述时仍会失手——例如,当熟悉的物体和关系被重新排列,并以全新的方式进行描述时,模型往往难以准确理解。
研究团队使用专门设计的测试来检验模型是否能像人类一样整合概念。然而,许多模型在这些测试中的表现接近随机猜测,说明它们难以捕捉词语与图像之间更细腻的对应关系。
在深入分析后,朱英伦团队发现,现有的评估方式本身可能对模型并不公平。
他指出,目前广泛采用的评估指标依赖于将图像和文本一对一地孤立比较,这种额外的约束可能会遮蔽图像与标题之间真正最优的整体匹配关系。
为此,团队提出了一种新的评估指标,能够在一组图像—标题候选中寻找整体最优的匹配方案。采用这一指标后,模型得分明显提升,也暴露出此前未被发现的潜在能力。
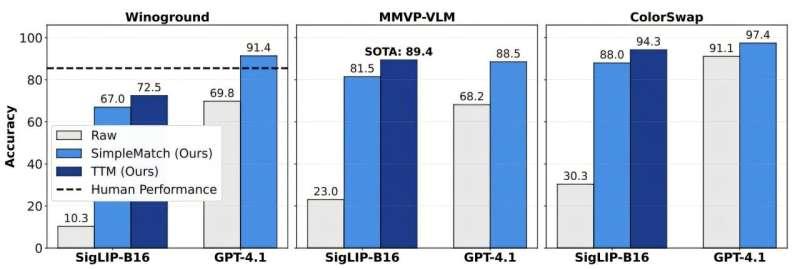
在这一洞见基础上,研究人员进一步提出了测试时匹配(TTM)技术,使人工智能系统可以在没有外部标注或监督的情况下,利用测试过程本身进行自我改进。
具体做法是:模型首先对图像与标题的匹配关系进行预测,从中选出自己最有把握的一部分预测结果,再用这些高置信度样本对自身进行微调,然后反复迭代这一过程,以持续优化性能。这个自我提升的循环过程,某种程度上模拟了人类利用上下文信息不断修正和强化推理的方式。
研究团队在 SigLIP-B16 模型上验证了 TTM 的效果。SigLIP-B16 是一个相对小型的视觉—语言模型,用于理解并关联图像与文本信息。引入 TTM 后,SigLIP-B16 在多个组合推理基准上的表现大幅提升,达到或超过此前的最先进水平。
在其中一项名为 MMVP-VLM 的基准测试中,TTM 将 SigLIP-B16 的表现提升到 89.4%,成绩超过了 GPT-4.1。
“即便是较小的模型,也蕴含着强大的推理潜力,”朱英伦表示,“我们需要做的,是通过更合理的评估方式和更聪明的测试时策略,把这种潜力释放出来。”
研究结果表明,像 TTM 这样的测试时适应策略,可能成为人工智能走向机器人、自主驾驶车辆和医疗等现实应用领域的关键工具——这些场景要求系统能够在缺乏额外标注数据的情况下,迅速适应全新的环境和任务。
朱英伦的工作也对“模型越大越好”这一普遍看法提出了挑战。他呼吁重新审视人工智能系统的评估与部署方式:“有时候,问题不在模型本身,而在于我们究竟是如何使用它的。”









