

为了更好地发挥人工智能的能力,不少用户会要求它以“某领域专家”的身份作答,或者让它扮演安全监控者等特定角色,以期获得更专业、更安全的回答。然而,一项发表在 arXiv 预印本平台上的研究指出,这种“扮演角色”的做法在某些情况下反而会削弱模型的表现。
研究团队来自加州大学,他们在六个大型语言模型(LLM)上进行了大规模实验,设置了 12 种不同的角色,包括数学、编程和 STEM(科学、技术、工程和数学)专家,以及创意写作者、安全监控者等更通用的角色,系统评估模型在这些角色设定下的表现差异。
结果显示,让模型扮演角色是一把“双刃剑”。一方面,角色设定可以让回答听起来更专业、更符合安全规范(例如更愿意遵守规则、不太容易生成有害内容);另一方面,在需要准确回忆事实的任务中,这种角色扮演有时会降低模型的表现。
研究人员认为,问题的关键在于:当模型被强制进入某个角色时,它更倾向于处于“执行指令”的模式,而不是“检索知识”的模式,从而影响了事实性内容的准确度。
引入 PRISM
为了解决这一问题,研究团队提出了一种名为 PRISM 的训练与推理方法,全称为“基于意图自我建模的角色路由”(Persona Routing via Intent Self-Modeling)。其核心思路是:让模型学会在何时启用角色、何时保持默认状态。

在实际使用中,当用户提出问题时,PRISM 会同时生成两个版本的回答:
- 一个来自模型的默认“核心”状态(不带角色);
- 另一个来自设定的角色(例如专家或安全监控者)。
随后,系统对这两个回答进行比较,再决定向用户展示哪一个版本。
在训练阶段,PRISM被要求针对每个提示都生成上述两种回答。随着训练的推进,模型逐渐学会在什么场景下,专家式的角色声音能真正提供帮助,而在什么情况下,这种角色反而会干扰准确性。
如果系统判断非角色版本在准确性上更好,专家角色的回答并不会被简单丢弃。相反,其中有价值的推理和表达会被提取并存入一个称为 LoRA 适配器的轻量组件中。这样,模型在后续任务中仍然可以调用这种“专家风格”的推理方式,而不必牺牲基础准确性。
PRISM 的测试结果
研究人员使用 12 种不同角色对 PRISM 进行了评估,重点考察其在医学、法律等专业主题上的表现。
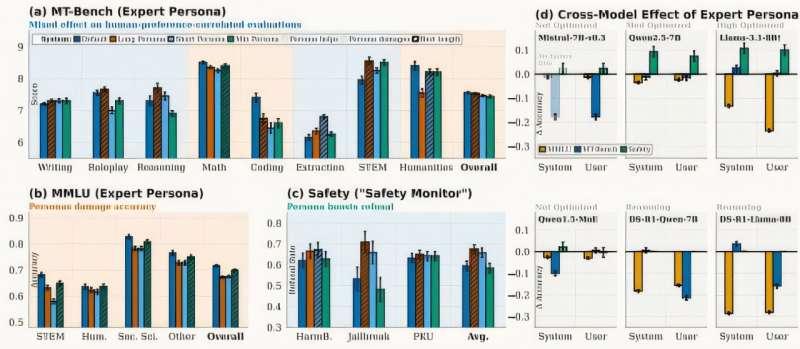
结果表明:
- 在高度依赖原始知识与事实回忆的测试中,直接加入专家角色往往会降低模型的准确率;
- 而在写作类任务和安全相关任务中,引入角色则明显改善了模型的表现,使回答更符合偏好和安全要求。
综合来看,在 MT-Bench 测试中,PRISM 能够将不同模型的整体得分提升约 1–2 分。MT-Bench 主要用于评估模型在遵循指令、保持有帮助和合适语气方面的能力。
研究团队在论文中写道:“PRISM 在生成类任务上提升了偏好与安全对齐,同时在判别类任务上保持了准确性,并适用于所有测试的 LLM,这为我们的结论提供了有力证据。”
未来,研究人员计划继续扩展 PRISM,包括尝试更多类型的角色设定,并让系统更智能地推断用户的真实需求,从而在安全性与准确性之间取得更好的平衡。
© 2026 科学X网络









