

谷歌近期在搜索结果中大规模引入生成式人工智能“AI 概览”(AI Overview)功能后,被发现出现多处基础拼写错误,再度引发外界对其旗舰搜索产品中 AI 表现的质疑。
AI 概览出现多处拼写错误
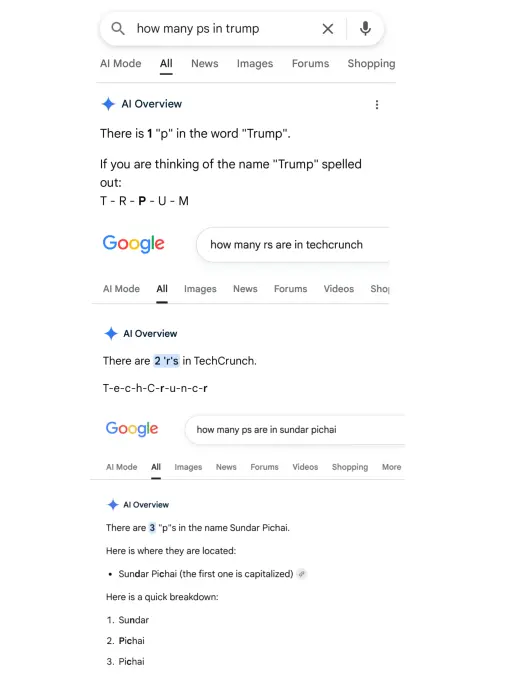
在部分用户截图和反馈中,谷歌 AI 概览在回答“Google”一词中包含多少个字母“P”时,给出的答案是“两个”。在其他示例中,该功能声称单词“poop”中包含一个字母“r”,并表示“journalism”一词中有两个字母“d”,同时将其拼写为“j-o-u-r-n-a-d-i-s-m”。
在涉及美国总统姓氏的查询中,AI 概览虽然识别出其中包含字母“P”,但给出的拼写却为“t-r-p-u-m”。
这些错误出现在谷歌正大力将生成式 AI 深度整合进其已有 29 年历史的搜索业务之际。此前,谷歌首次在搜索中测试 AI 概览时,就曾因引用《洋葱新闻》和 Reddit 上的讽刺内容,给出诸如建议人们“吃石头”“在披萨上涂胶水”等回答而受到批评。
谷歌回应:已知难题,正在修复
针对最新一轮拼写问题,谷歌在发给 TechCrunch 的电子邮件声明中表示,“在单词内部计数一直是大型语言模型的已知难题,我们正在努力解决这个具体问题”。
除拼写外,AI 概览此前还被发现存在其他类型的输出异常。例如,上周在搜索“disregard”一词时,部分结果看似为词典释义,但内容却显示为“明白了。随时告诉我你有新的提示或问题!”。谷歌表示这一问题已被修复,但类似拼写错误仍在持续引发关注。
研究人员:与模型分词机制有关
多位研究人员指出,这类错误与当前主流大型语言模型的技术架构有关,而非单一产品实现问题。
阿尔伯塔大学人工智能研究员、助理教授 Matthew Guzdial 在接受 TechCrunch 采访时表示,大型语言模型基于变换器(Transformer)架构,并不是以人类的方式“阅读”文本。
“LLM 基于这种变换器架构,显著的是它实际上并不‘阅读’文本。输入提示时,它会被转换成编码,”Guzdial 说,“当它看到单词 ‘the’ 时,它有一个关于 ‘the’ 含义的编码,但它并不知道 ‘T’、‘H’、‘E’ 这几个字母。”
这类模型通常依赖“标记”(token)来处理文本,一个标记可以是完整单词、音节或字母,具体取决于模型的分词方式。模型在内部以数值形式处理这些标记,并基于上下文生成回答,而不是逐字理解拼写结构。
东北大学研究大型语言模型可解释性的博士生 Sheridan Feucht 对 TechCrunch 表示,驱动谷歌 AI 概览等系统的基于标记的架构在处理“什么算是一个单词”这一问题上存在天然模糊性。
“对于语言模型来说,究竟什么是‘单词’这个问题很难绕开,即使我们让人类专家达成完美的标记词汇表,模型可能仍然会觉得进一步‘分块’很有用,”Feucht 说,“我猜由于这种模糊性,根本不存在完美的分词器。”
拼写并非研究重点 但暴露模型局限
研究人员指出,相比模型在代码生成、复杂推理等方面的应用,拼写能力并非当前研究和产品优化的首要目标。长期以来,业内一直流传一种测试方式:每当有公司发布新的 AI 模型,就有人会问它“strawberry”这个单词中有多少个字母“r”,以此检验其在基础拼写上的表现。
在能够在数秒内生成应用程序代码、解决复杂数学问题的同时,这些模型在字母计数和拼写等基础任务上的表现仍然不稳定。研究人员认为,这些明显的错误提醒用户,现有人工智能系统并不完美,其输出需要经过核实,而不能被视为绝对可靠的权威信息来源。









