

中国阿里巴巴旗下的 AI 研究团队 Qwen 于 2026 年 6 月 16 日发布了面向机器人开发的 AI 模型套件「Qwen-Robot Suite」。这一套件由三个基础模型组成,分别负责机器人移动、物体操作以及物理世界预测,旨在把 Qwen 多模态大模型的能力,从纯数字空间扩展到真实物理空间中的机器人系统。
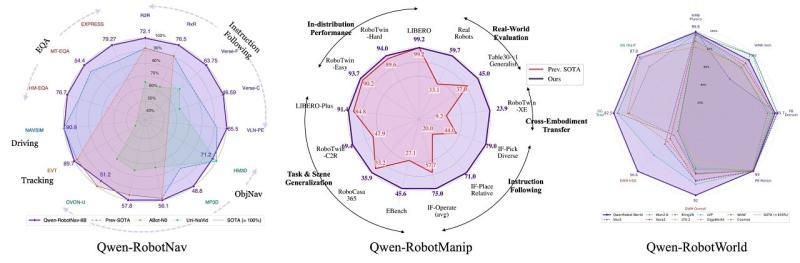
■ Qwen-RobotNav、Qwen-RobotManip、Qwen-RobotWorld 的评测概览:在导航、物体操作和世界模型三大领域,对各模型性能进行了对比
三大核心模型:移动、操作与世界预测分工协作
Qwen-Robot Suite 由 Qwen-RobotManip、Qwen-RobotNav 和 Qwen-RobotWorld 三个模型构成,分别对应机器人操作、导航和世界建模三类关键能力。
Qwen-RobotManip 是面向机器人手臂等执行机构的 Vision-Language-Action(VLA)模型,主要解决「如何操作物体」的问题。它将视觉信息、自然语言指令与机器人自身状态关联起来,用于完成抓取、移动、整理物品等操作任务。
Qwen-RobotNav 负责机器人在环境中的导航与移动。它面向的场景包括:根据指令在空间中移动、寻找指定物体、跟踪目标,以及在类似自动驾驶的场景中,利用周围视觉信息进行路径规划和决策。
Qwen-RobotWorld 则是一个视频世界模型,用于预测物理世界的未来变化。模型基于当前观测,推断接下来可能出现的视觉变化,可用于合成数据生成、虚拟环境评估,以及为机器人控制提供规划信号,让机器人在「真正行动之前」先在模型中预演结果。
操作模型:基于约 3.81 万小时数据的预训练
在 Qwen-RobotManip 的技术报告中,研究团队将其定位为基于 Qwen-VL 的通用 VLA 模型。团队整合了开源机器人操作数据、人类第一视角视频以及合成数据,构建了约 3.81 万小时规模的预训练语料。
其中一个关键设计是「Human-to-Robot」合成管线:将人类第一视角的操作视频转换为适配 15 种不同机器人形态的操作数据。通过这一过程,人类手部动作被映射为不同机器人平台的轨迹表示,从而在多种机械结构之间对齐动作表达。
报告指出,与文本或图像相比,机器人操作数据的采集成本更高,而且不同机器人的形态和控制方式差异很大,简单堆砌数据难以获得良好的泛化能力。为此,Qwen-RobotManip 在状态与动作表示、末端执行器(End-Effector)运动描述以及执行历史的编码方式上进行了统一,使不同机器人之间更容易共享学习信号。

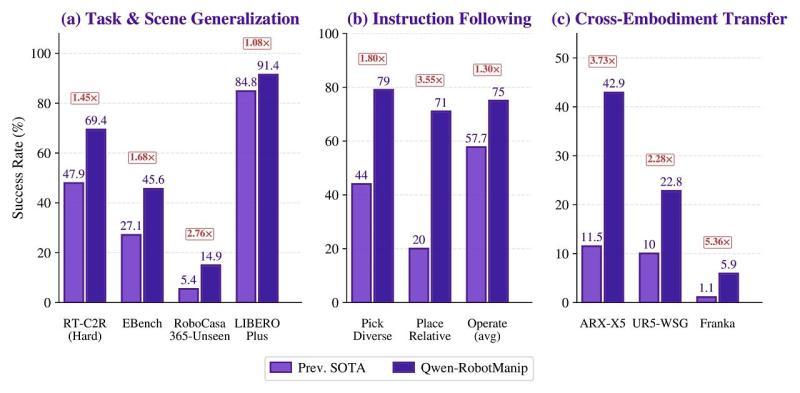
■ Qwen-RobotManip 的 OOD(分布外)泛化能力概览:在任务与场景泛化、指令跟随、跨机器人形态迁移等方面,与既有方法进行了对比
导航与世界模型:为机器人系统提供「眼睛」和「大脑」
根据 Qwen-RobotNav 的技术报告,该模型基于 Qwen3-VL 构建,专注于导航任务。训练过程中使用了约 1550 万条样本,覆盖指令跟随、物体搜索、目标追踪、自动驾驶等多种导航场景,并在统一的感知与规划框架下进行建模。
Qwen-RobotNav 并非一个独立完成所有任务的「全能体」,而是面向上层 AI 代理(Agent)的可调用组件。在长周期、复杂任务中,通常由上层规划器负责拆解目标,Nav 模型则根据当前环境和子目标,执行具体的移动与探索行为。
另一方面,Qwen-RobotWorld 是面向具身智能(Embodied AI)的、带语言条件的视频世界模型。它在包含 860 万段视频-文本对、超过 2 亿帧画面、20 多种具身形态以及 500 余类动作类别的数据上进行训练,目标是在给定当前观测和语言条件的前提下,预测物理一致的未来视觉轨迹。
世界模型有望成为机器人在真实环境中反复试错之前的「虚拟试验场」。在本次发布的套件中,移动、操作与世界预测被拆分为三个专门模型,同时又与 Qwen 系列基础模型相衔接,勾勒出一个可组合的机器人智能架构方向。
从聊天模型到「能在物理世界行动的 AI」
迄今为止,生成式 AI 的主要应用集中在文本、图像、视频、音频等数字内容的理解与生成上。Qwen-Robot Suite 则尝试把这些基础模型的能力延伸到机器人领域,让机器人能够在真实世界中移动、操作物体并预测环境变化。
阿里云方面表示,该套件已经与部分机器人行业企业客户展开试点测试。不过,本次发布的对象是用于机器人开发的 AI 模型,而非具体的机器人硬件产品。面向普通用户的开放范围以及商业化使用条件,还需等待后续官方进一步说明。
在机器人领域,采用多种基础模型按功能分工协作,而非依赖单一专用模型的趋势正在加速。Qwen-Robot Suite 的推出,表明阿里巴巴正尝试将 Qwen 从聊天与多模态内容生成,扩展到能够在物理世界中执行任务的具身智能方向。









