

虚拟现实(VR)体验和360度视频正在把观众从被动的“看客”变成沉浸在场景中的主动参与者。但随之而来的一个关键问题是:在这样可以自由环顾四周的环境中,人们的注意力究竟会集中在什么位置,又受到哪些因素影响?
由 Koç 大学计算机工程系副教授 Aykut Erdem 博士领衔的一项最新研究,给出了新的答案。相关成果发表在《IEEE 模式分析与机器智能汇刊》上。该工作由 Koç 大学与博阿齐奇大学心理学系视觉实验室、哈切特佩大学以及日本先进工业科学技术研究所(AIST)研究人员共同完成。
这项研究的核心创新在于:不再只依赖视觉信息,而是同时分析视觉和听觉线索,来预测观众在360度视频中的注意力分布。
在传统的平面视频中,摄像机的取景框天然限定了观众的视野范围,镜头语言在很大程度上引导了视线。而在360度视频中,整个场景都被呈现出来,观众可以随时向任意方向观看,注意力的走向因此变得更加难以预测。
在这种情况下,声音就变得尤为重要。类似于日常生活,当我们听到某个方向传来声音时,往往会下意识地转头去看。然而,以往针对注意力的研究大多聚焦于视觉数据,对声音如何参与塑造注意力的系统性探讨相对有限。
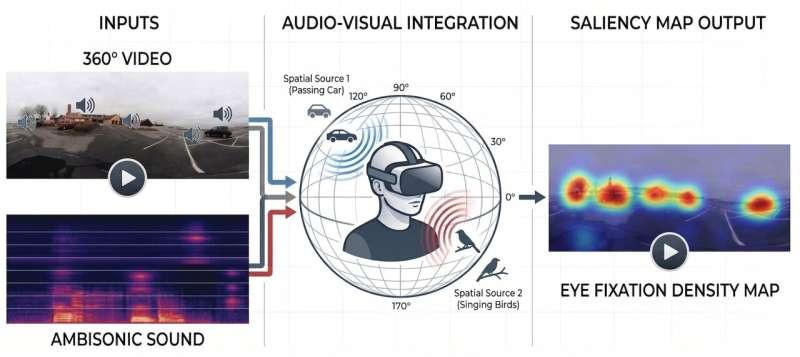
为弥补这一不足,研究团队构建了一个综合数据集,用于分析视觉与听觉线索之间的相互作用。该数据集包含 81 段不同场景的360度视频,并在三种音频条件下呈现:静音、单声道以及空间声音。空间声音技术可以模拟声音来自特定方向的感受,更接近真实世界中的听觉体验。研究人员通过记录 100 多名参与者的眼动轨迹,细致比较了不同听觉条件下注意力分布的变化。
在此基础上,团队提出了两种专为360度视频数据结构设计的 AI 模型:
- 第一种模型仅利用视觉信息进行预测;
- 第二种模型在视觉基础上进一步引入音频特征,从而更全面地刻画注意力分布。
借助第二种模型,系统不仅能够识别画面中视觉上显著的区域,还能捕捉那些虽然视觉上不突出,但由于声音而吸引观众视线的位置。
实验结果显示,引入音频信息后,模型在预测观众注意力方面的性能有明显提升。尤其是在使用空间声音时,模型既能准确锁定视觉显著区域,又能发现那些主要由声音驱动的注意力热点。
总体来看,这项研究表明,如果在建模时同时考虑人们如何在视觉和听觉刺激之间分配注意力,就能更贴近真实的人类注意力模式。除了理论上的贡献,这一方法在多个实际场景中也具有应用潜力,例如:视频压缩与传输优化、沉浸式内容创作、主观质量评估,以及 VR/AR 等沉浸式环境中的用户体验设计等。









