



用鸟类鸣叫训练,却能识别鲸鱼和海豚
Google DeepMind 开发的生物声学基础模型 Perch 2.0,虽然主要是用鸟类等陆生动物的鸣叫声进行预训练,却在鲸鱼、海豚等海洋哺乳动物的水下声学分类任务中表现出意外优异的效果。相关研究成果目前已以预印本形式发布在 arXiv 上。
以鸟类为核心构建的大规模生物声学模型
Perch 2.0 是一个面向生物声学场景的大规模基础模型,训练数据以鸟类为主,涵盖多种陆生动物的叫声。模型从原始音频波形和频谱图中提取抽象的声学特征,并将其表示为可通用的 嵌入向量(embedding)。
这些嵌入可以作为通用特征,被下游任务复用:
- 直接接入简单的线性分类器
- 在少量标注数据上进行轻量级微调
通过这种方式,Perch 2.0 被设计成一个可迁移到多种生物声学分类任务的基础模型,而不局限于鸟类识别。
为什么“用鸟学出来的 AI”能在“鲸豚任务”上奏效?
研究的核心问题是:以陆生动物为主的预训练,为什么能在水下这一全新声学环境中依然保持高性能?
Perch 2.0 在设计时特别强调 线性探测(linear probing) 场景下的迁移能力。也就是说,在下游任务中固定预训练好的嵌入,仅训练一个简单的线性分类器,就能取得不错的效果。这种方式对计算资源和标注数据的需求都很低,非常适合生态监测等数据稀缺场景。

论文从以下几个角度解释其跨领域迁移能力:
-
“Bittern Lesson” 假说: 在鸟类鸣叫识别中,不同物种之间的差异往往极其细微,属于难度很高的精细分类任务。在这类任务上进行大规模训练,可能迫使模型学到更加通用、精细且可泛化的声学表征,从而在其他物种和环境中也能发挥作用。
-
规模效应(Scaling)带来的鲁棒性: 随着训练数据量和模型规模的扩大,模型在“域外任务”(如从陆地转向水下)的表现往往会更稳健,能够更好地适应此前未见过的声学分布。
-
发声机制的物理共性: 鸟类与海洋哺乳动物在发声结构和声学物理特性上,可能存在一定程度的共通之处,使得模型学到的特征在不同物种之间仍然适用。
在海洋哺乳动物数据上的验证
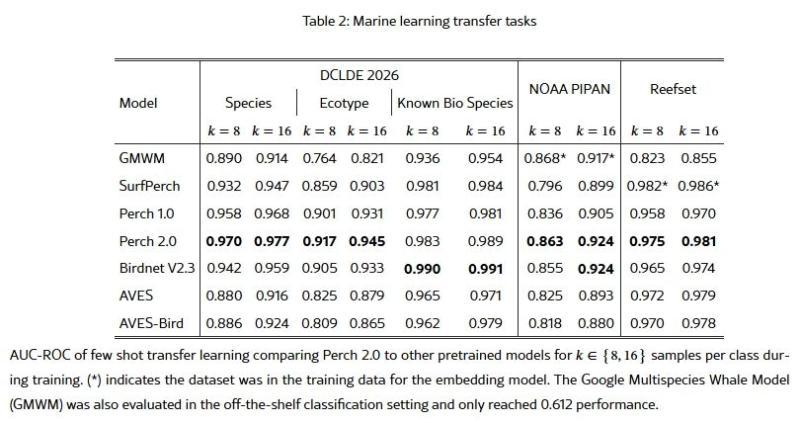
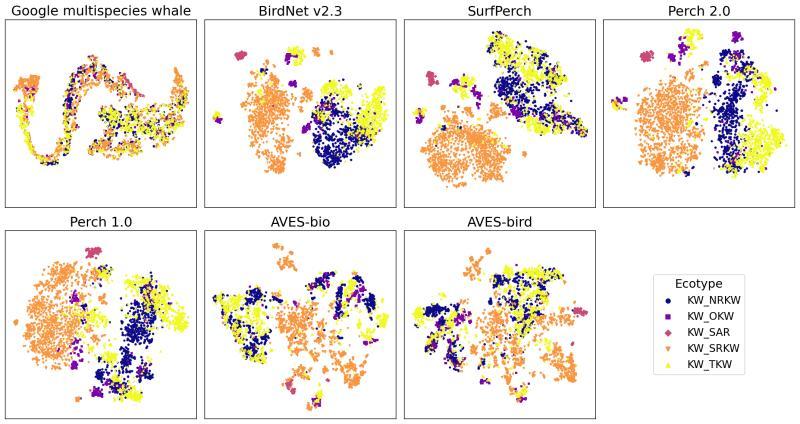
研究团队使用 Perch 2.0 生成的声学嵌入,对包含鲸鱼、海豚等海洋哺乳动物的水下录音数据进行了分类实验,并采用 F1 分数、平均准确率(mAP) 等指标进行评估。
结果显示,在多个海洋哺乳动物数据集上:
- Perch 2.0 的表现与现有的专用模型及其他声学基础模型相当,甚至在部分任务上有所超越;
- 即便只在固定嵌入上训练一个线性分类器(线性探测设置),也能取得较高分数,凸显了预训练表征本身的质量。
此外,在 few-shot(小样本) 条件下,仅使用极少量标注样本训练分类器,性能下降也相对有限。论文指出,这意味着在标注资源稀缺的情况下,依托 Perch 2.0 仍然可以构建出实用水平的海洋哺乳动物分类器。
面向生物多样性监测的应用前景
根据 Google DeepMind 官方博客的介绍,团队正尝试将生物声学 AI 应用于:
- 绝灭危惧物种的自动检测
- 大规模、长期的生态系统监测
- 从长时间录音中自动检索特定物种的存在证据
Perch 系列模型已与多家保育组织和研究机构合作,用于从海量录音中自动识别物种。此次关于海洋哺乳动物的实验结果,也被视为这一生物声学研究路线的重要延伸:
- 一方面验证了跨物种、跨环境的迁移潜力;
- 另一方面为在数据有限的海洋生态监测场景中部署 AI 工具提供了技术依据。
从更长远的角度看,这类通用生物声学基础模型,有望成为全球生物多样性监测基础设施的一部分,帮助研究者在更大空间和时间尺度上追踪物种动态与生态变化。









