

Meta 于 2026 年 3 月 26 日发布了一款能够预测人类大脑对视频、音频、语言等多种刺激反应的 AI 基础模型「TRIBE v2」。相关研究成果已在 Meta AI 官方博客和研究演示页面公开,配套论文也同步发布。
TRIBE v2 的目标,是在不给真实受试者做实验的前提下,仅通过计算机模拟来预测大脑活动,从而支持所谓的“虚拟实验”(in-silico neuroscience,计算机上的神经科学研究)。
融合视频・音频・语言的三模态基础模型
TRIBE v2 被设计为一个同时处理三种模态的基础模型:
- 视频(video)
- 音频(audio)
- 语言(language)
当输入电影片段、语音、文本等刺激时,模型会预测人类大脑在这些刺激下的活动模式,并以 fMRI(功能性磁共振成像)中可观测到的脑区激活形式给出结果。与以往多聚焦于“视觉专用”“听觉专用”等单一刺激的脑活动模型不同,TRIBE v2 能在更接近真实生活的多感官情境下,对大脑反应进行统一建模和预测。
在模型结构上,TRIBE v2 组合了 Meta 既有的多种 AI 模型:
- 使用视频理解模型「V-JEPA2」提取视觉特征
- 使用音频模型「wav2vec 2.0」提取声音特征
- 使用语言模型「Llama 3.2」提取文本与语义特征
随后,这些来自不同模态的特征会被输入到 Transformer 结构中进行融合,最终输出对人脑活动的预测结果。
TRIBE v2 的模型结构:通过 V-JEPA2(视频)、wav2vec 2.0(音频)、Llama 3.2(语言)提取特征,再由 Transformer 进行多模态融合,预测人类大脑的活动模式。


基于约 720 名受试者、超 1000 小时脑活动数据训练
论文指出,TRIBE v2 使用了来自约 720 名受试者、总时长超过 1000 小时的 fMRI 数据进行训练。

这些数据涵盖了多种自然情境下的大脑活动,例如:
- 观看电影
- 聆听语音或音乐
- 阅读和理解文本
通过将大规模、跨任务、跨模态的神经活动数据整合到同一训练框架中,模型得以学习人类大脑在不同刺激条件下的反应模式。研究报告称,与以往的脑活动预测模型相比,TRIBE v2 在预测精度上实现了数倍的提升。
模型预测与真实脑活动高度吻合
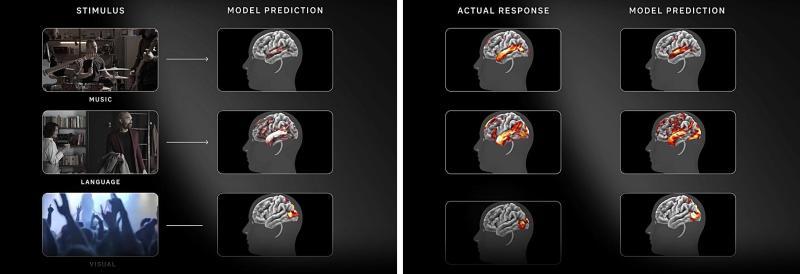
TRIBE v2 能针对音乐、对话、视频等不同类型的刺激,预测人脑在相应条件下的活动分布。论文中展示的结果表明,在多种刺激条件下,模型预测的脑活动与实际 fMRI 测量结果之间具有高度一致性。
示例:对音乐、语言、视频等刺激条件下的大脑活动,比较真实 fMRI 数据(Actual Response)与 TRIBE v2 的预测结果(Model Prediction)。在多种刺激场景中,两者呈现出高度相似的空间分布与变化趋势。
将神经科学研究迁移到“计算机上的实验”
传统的脑科学研究往往需要:
- 招募并筛选受试者
- 设计和反复调整实验范式
- 安排 fMRI 等昂贵且耗时的脑成像测量
这些步骤不仅成本高、周期长,也限制了研究假设的迭代速度。
借助 TRIBE v2 这类模型,研究者可以在计算机上直接输入各种刺激条件,观察模型给出的脑活动预测结果,用于初步验证假设或探索大脑功能分布。Meta 将这种方式称为「in-silico neuroscience」,即“计算机上的神经科学”。
目前,Meta 已开放 TRIBE v2 的在线演示页面,用户可以在浏览器中体验模型如何根据不同刺激预测脑活动。对于神经科学和 AI 交叉领域的研究者而言,TRIBE v2 有望成为连接大规模脑数据与通用 AI 模型的重要基础设施,并推动更多关于大脑机理与智能本质的研究。









