

人工智能在数学领域的表现近年引发关注:一些系统已能完成国际数学奥林匹克竞赛题目求解、进行大规模文献检索,甚至在个别长期难题上给出解决思路。但多位一线研究者表示,这类成果并不等同于在研究数学前沿与顶尖专家“同台竞争”。
在此背景下,来自哈佛大学、斯坦福大学等机构的数学家发起“First Proof”项目,试图以更可重复、相对独立的方式,界定人工智能与人类数学研究能力之间的边界。项目组织者向人工智能公司提出挑战:要求系统破解一组由数学家近期解决但尚未公开发表的研究级问题,并将人工智能给出的证明与人类证明进行对照。
哈佛大学数学系教授劳伦·威廉姆斯(Lauren Williams)表示,人工智能能力持续提升,使得评估变得更复杂;但就目前而言,系统在“创造性飞跃”以及处理远超既有题型的难题方面仍表现不足。威廉姆斯近期获得麦克阿瑟基金会“天才奖”。
“First Proof”由斯坦福大学数学教授穆罕默德·阿布扎伊德(Mohammad Abouzaid)发起,组织团队共11名数学家,其中包括一位菲尔兹奖得主和两位麦克阿瑟“天才奖”获得者。阿布扎伊德称,一些广为传播的人工智能数学能力展示“并未真正反映我作为数学家的经验”。他指出,科技公司往往更关注可自动化、可规模化衡量的结果,并可能将研究问题改写成更适合现有技术回答的形式;此外,部分研究由利益相关方主导。
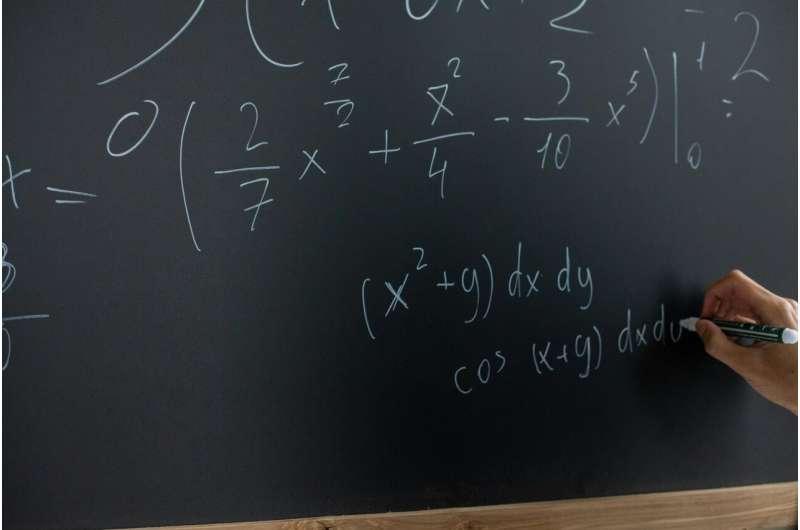
人工智能在竞赛数学上的进展已被公开报道。2024年,谷歌DeepMind开发的系统在国际数学奥林匹克竞赛题目上达到相当于银牌得主的水平。不过,另一项最新分析认为,大型语言模型在研究级数学问题上仅能解决极少数题目,且容易出现逻辑错误、基本误解以及对既有结果的“幻觉”。一些研究者据此认为,当前工具更适合承担文献综述等繁琐辅助工作,而非独立完成重大研究问题的攻关。
为进行独立评估,来自哈佛、哥伦比亚、杜克、耶鲁、加州大学伯克利分校、得克萨斯大学奥斯汀分校等机构的数学家团队于去年12月在伯克利会面,汇集了10个“近期解决但尚未发表”的研究问题,覆盖数论、代数组合学、谱图论、辛拓扑学和数值线性代数等方向。组织者称,每道题的解答均不超过五页,已加密存放于安全库中。
项目网站于2月5日公开题目,并计划于2月13日公布解答。组织者表示,鉴于同一问题可能存在多种证明路径,后续将比较数学家与人工智能给出的证明,并计划在今年晚些时候发布新一组问题。
根据作者对GPT 5.2 Pro和Gemini 3.0 Deepthink的初步测试记录,“目前公开可用的最佳人工智能系统在回答我们许多问题时表现挣扎”。阿布扎伊德表示,初测中模型在10个问题里解决了两个,并称“通过观察它能回答哪些问题,我们已经学到了很多”。
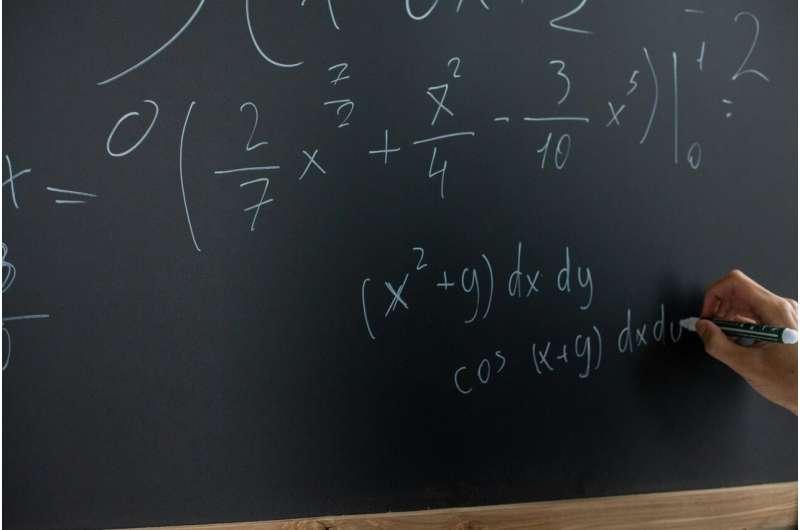
威廉姆斯也分享了她在使用人工智能工具时的体验:当问题不在其熟悉领域时,系统给出的回答往往看似信息充分;但当问题接近其专业方向时,错误开始增多。她称,系统有时会出现“幻觉”,例如声称某个答案出自她“写过的论文”,甚至编造引用;她之所以能识别,是因为系统把她列为作者,而她从未写过相关论文。她还表示,系统有时会曲解提问,将原问题转向可从既有文献直接回答的另一个问题。
威廉姆斯认为,人工智能在模仿既有成果、组合已知结果进行推演,以及处理算法性问题方面表现较好,但这并不等同于研究前沿的突破。她指出,研究数学通常包括提出好问题、构建解决框架、完成求解三个阶段,而前两步仍超出当前人工智能能力范围,因此此次挑战主要测试第三步——在已定义问题上寻找解答。
项目合著者之一、瑞士洛桑联邦理工学院与伦敦帝国学院纯数学教授、2014年菲尔兹奖得主马丁·海勒(Martin Hairer)表示,团队希望对“数学已被解决”的说法作出回应,这类说法往往源于某些大型语言模型解出部分奥赛题目。他称,就目前而言,“数学家会被人工智能取代”的说法并不成立。
本文信息源自哈佛大学官方报纸《哈佛公报》授权发布内容。









