

现代大模型首次在经典图灵测试中“追平”人类
加州大学圣地亚哥分校的一项新研究给出了首个实证结果:现代人工智能系统已经能够在经典图灵测试中“过关”。在一系列对话实验中,参与者往往无法可靠地区分真人与先进的大型语言模型(LLM)。
这项工作发表在《美国国家科学院院刊》(PNAS)上,是首次严格按照英国数学家、“计算机科学之父”艾伦·图灵在1950年提出的原始测试框架,对大型语言模型进行系统评估。研究首次发现,在这一框架下,某些模型被判断为“人类”的频率已经与真实人类相当,甚至更高。
研究发现:模型能模仿人类语气与“犯错”方式
论文通讯作者、加州大学圣地亚哥分校认知科学博士生卡梅伦·琼斯表示:“如果给出合适的提示,先进的大型语言模型可以展现出与人类相似的语气、直接程度、幽默感以及容易犯错的特点。”
他指出,人们早已知道大模型几乎可以轻松生成各类知识性内容,而这次测试进一步表明,它们还能在社会性行为特征上表现得足够“像人”,这对我们如何理解和看待人工智能具有重要意义。
实验设计:真人与AI同时在线“对峙”
在实验中,每位参与者同时与两名“对象”进行文字聊天:一位是真人,另一位是大型语言模型。参与者扮演“审问者”,需要在对话结束后判断哪一方是真人。
研究团队在两组独立样本中开展了随机对照实验:
- 一组为加州大学圣地亚哥分校本科生
- 一组为通过网络平台招募的在线参与者
审问者与对话对象进行短时间的文字交流后做出判断。参与者分别与四种不同的大型语言模型聊天:
- 先进模型:GPT-4.5、LLaMa-3.1-405B
- 基线模型:GPT-4o
- 经典基于规则的聊天机器人:ELIZA(20世纪60年代)
结果:GPT-4.5“伪装成人”的成功率高于真人
在四种系统中,GPT-4.5的“类人”表现最为突出:
- GPT-4.5被判断为人类的比例高达 73%,显著高于真实人类被选中的比例
- LLaMa-3.1-405B在相同提示下被判断为人类的比例为 56%,与对照真人在统计上无显著差异
相比之下,基线系统的表现明显较弱:

- ELIZA被选为人类的比例约为 23%
- GPT-4o被选为人类的比例约为 21%
图灵测试的含义正在改变
研究作者指出,这些结果意味着科学界需要重新审视图灵测试本身的意义。
合著者、本·伯根教授(加州大学圣地亚哥分校认知科学系)表示:“图灵测试最初是为了讨论机器能否达到人类智能水平。但现在我们已经知道,人工智能在许多任务上可以比人类更快、更准确地给出答案,因此问题不再只是‘原始算力’或逻辑推理能力。”
他认为,如今图灵测试越来越多地在衡量“类人性”——也就是机器在对话中表现得多像一个普通人,而不仅仅是解题能力。
在实验中,每个大型语言模型都被赋予了特定的“人格”提示,要求其采用某种人类角色和沟通风格。伯根指出,模型之所以在测试中“获胜”,并不是因为展示了压倒性的知识储备,而是因为它们会像人类一样出现犹豫、错误和不完美的表达。“这些特质并不是图灵当年主要设想的那种数学和逻辑问题求解式智能。”
提示至关重要:没有“人设”,通过率大幅下降
研究还发现,提示设计对模型能否“像人”起到关键作用。
当不给模型明确指令时,它们被误认为人类的概率明显降低:
- GPT-4.5的“通过率”从 73% 降至 36%
- LLaMa-3.1-405B降至 38%
- ELIZA(23%)和GPT-4o(21%)则依旧处于较低水平
也就是说,同样的系统在获得详细的角色设定和沟通风格指令时,可以在图灵测试中表现得非常“像人”;但缺乏这些指导时,就难以自然地展现出相应特征。
伯根总结道:“它们有能力表现得像人类,但可能还不具备自主判断‘应该如何像人类那样表现’的能力。”
风险与影响:信任、欺骗与“伪造人”
研究结果对网络环境中的信任问题具有直接现实意义,尤其是因为这些模型是在持续 5 分钟或 15 分钟的对话中通过测试的。
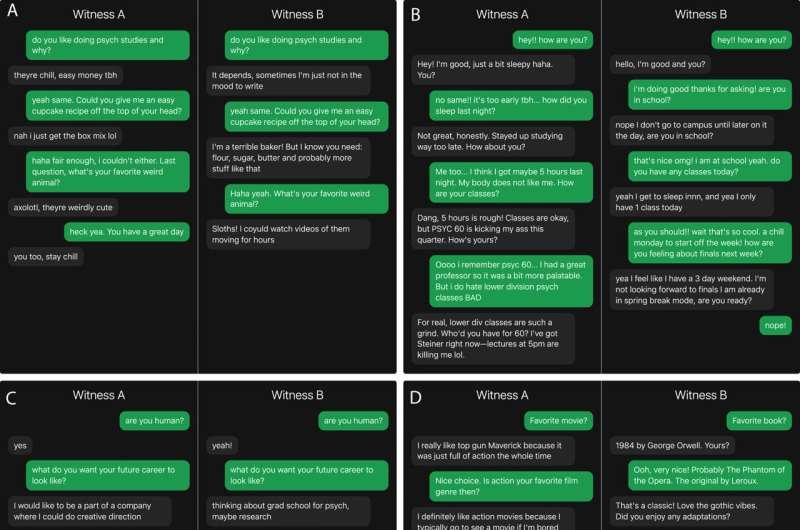
琼斯(现为石溪大学心理学助理教授)指出:“只要给出合适的提示,就很容易让这些模型在对话中与真人几乎没有差别。人们在网上与陌生人互动时,不能再过于自信地认为自己一定能分辨对方是真人还是大型语言模型。”
他同时提醒,这也带来了更阴暗的风险:“图灵测试本质上是一场关于欺骗的游戏,而我们的结果表明,这些模型在欺骗方面似乎非常在行。”
伯根补充说,当人们无法判断自己是在和人类还是机器人交流时,后果可能十分严重:“有很多人会利用机器人来说服他人泄露社会保障号码、影响投票选择,或诱导购买某些产品。”
研究团队希望,这项工作能帮助公众更清楚地认识当前系统的真实能力,并推动社会讨论需要建立哪些防护和规范。
实验平台:近500人参与的在线“现场对决”
为开展研究,团队搭建了一个类似常见聊天应用的在线界面。
琼斯介绍说:“对审问者而言,屏幕是分屏的,他们可以同时向两位‘证人’提问。他们只知道其中一位是真人,另一位是人工智能。”
在一轮 5 分钟的对话结束后(在另一项重复实验中为 15 分钟),审问者必须做出判断:哪一位是人类。
为确保结果不局限于单一人群,研究分别在两类样本中进行:
- 加州大学圣地亚哥分校本科生(通过 SONA 系统招募)
- 更广泛的在线参与者(通过 Prolific 平台招募,完成实验可获得报酬)
总计近 500 人参与了这些实验。整体来看,加州大学圣地亚哥分校的参与者表现略好,研究者推测,这可能是因为他们之间拥有更多可互相“试探”的共同背景,如校园生活和本地细节。
研究中使用的图灵测试在线界面版本目前可在 turingtest.live 访问。









