

加州理工学院(Caltech)孵化的 AI 初创公司 PrismML 宣布推出大规模语言模型(LLM)「1-bit Bonsai」。这是一款约 80 亿参数的模型,却将内存占用控制在约 1.15GB,体量足以在智能手机等边缘设备上本地运行。
通常来说,8B 级别的 LLM 往往需要十几 GB 的内存。PrismML 通过在模型结构和训练方法上的设计创新,大幅压缩了模型尺寸,同时声称在性能上仍能与同参数规模的主流模型竞争。
与传统量化不同的「1 比特设计」
在缩小 LLM 体积时,常见做法是对训练完成的模型权重进行低比特量化,将其从 16bit、8bit 压缩到更低精度。不过,当比特数降得过低时,模型精度往往会明显劣化,这是传统量化面临的主要难题。
PrismML 采取了完全不同的路径:不是先训练再压缩,而是从一开始就把模型设计成在 1 比特环境下工作。
具体来说,包括以下关键组件在内的整个模型,都以 1 比特为前提进行训练:
- 将输入文本转换为数值向量的嵌入层(Embedding)
- 负责处理上下文信息的注意力层(Attention)
- 生成输出的语言建模头(LM Head)
也就是说,模型并非事后被「压扁」,而是从训练之初就面向低比特环境进行优化,以此尽量降低精度损失。
模型尺寸与性能的平衡
PrismML 公布的对比结果显示,在保持极小模型尺寸的前提下,1-bit Bonsai 系列在多项基准测试中仍具备相当竞争力。
■ 模型尺寸与性能关系对比:1-bit Bonsai 系列在小体量下依然取得了有竞争力的基准测试成绩
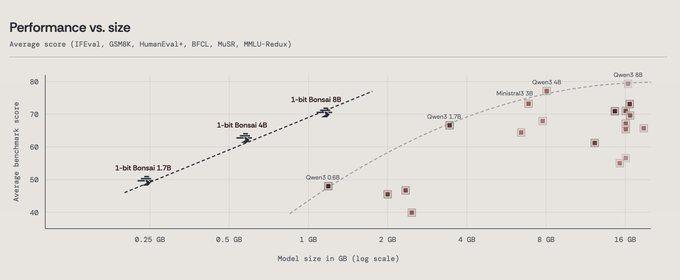
与同级别模型的基准测试对照
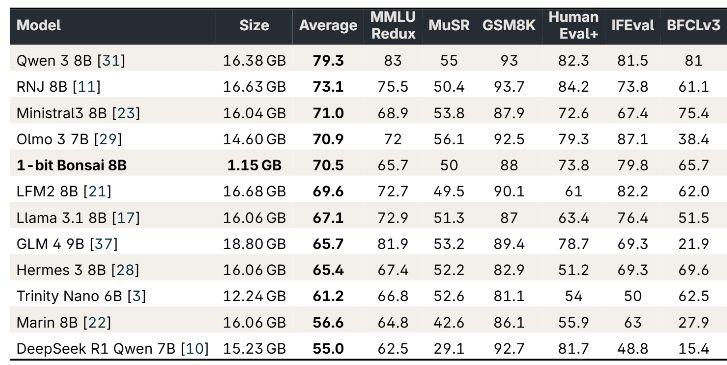
在 PrismML 公布的基准测试对比中,1-bit Bonsai 8B 的模型大小仅约 1.15GB,却在多个评测项目上取得接近主流 8B 级 LLM 的分数。
■ 与 8B 级 LLM 的基准测试对比:1-bit Bonsai 8B 在大幅缩小模型尺寸的同时,仍保持与同级模型相近的性能
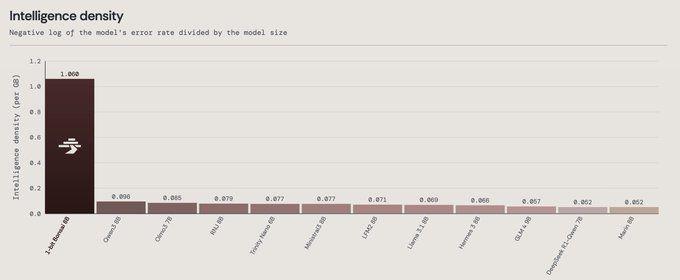
用「智能密度」衡量效率
PrismML 提出了一个用于衡量模型效率的新概念——「智能密度(Intelligence Density)」。

这一指标的定义是:将多个基准测试的平均错误率取负对数,再除以模型大小,得到单位模型容量所能承载的「智能」密度。数值越高,意味着在同样的存储空间下,模型能提供越多的有效智能能力。
根据 PrismML 的评估结果:
- 1-bit Bonsai 8B:1.06 / GB
- Qwen3 8B:0.10 / GB
在这一指标上,1-bit Bonsai 8B 远高于同参数规模的对比模型。
■ 「智能密度」对比:1-bit Bonsai 8B 显著高于同级别模型
面向本地与边缘场景的 AI 模型
1-bit Bonsai 的模型权重以 Apache 2.0 许可证开源发布。
据 PrismML 介绍,该模型可以通过以下方式在不同硬件上运行:
- 在 Apple 设备上通过 MLX 运行
- 在 NVIDIA GPU 上通过 llama.cpp CUDA 运行
过去,大模型多以云端推理为主。本次这类极度轻量化的 LLM 出现,意味着在 PC、手机等终端设备上直接本地运行 AI 的场景有望进一步扩展。
「AI 的未来不只在于变大」
PrismML 联合创始人、加州理工学院教授 Babak Hassibi 在 X(原 Twitter)的发文中,对公司的理念做出了概括:
「AI 的未来,并不只是模型越大越好。真正关键的是『智能密度』——在给定的算力、内存和能耗下,模型能提供多少有用的智能。」
他将 1-bit Bonsai 视为这一理念的首个落地案例:
「这不是终点,而是新 AI 范式的起点。智能将扩散到本地设备、边缘、云端,以及各种新产品和新系统之中。」









