

美国研究团队首次在人类试验中展示了一种脑控助听原型系统,可通过读取大脑信号自动放大听者“想听”的声音。研究人员称,这一技术有望为全球约4.3亿听力障碍者提供新的辅助工具。
读脑识别“注意对象”
该研究由哥伦比亚大学团队主导,相关成果已发表于《自然神经科学》(Nature Neuroscience)。
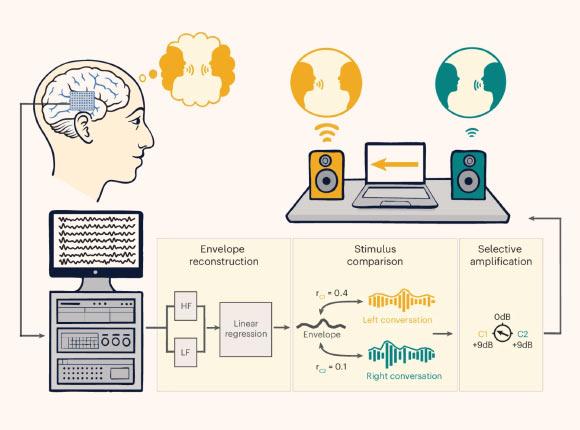
在试验中,参与者因癫痫治疗需要已植入颅内电极,并在医院接受脑部手术以更精确定位癫痫发作源。这些患者在知情同意后自愿参与研究。实验环境中,他们需要同时聆听两个来自不同空间位置的竞争性对话。
研究团队利用植入电极记录参与者在专注于其中一段对话时的大脑活动,并将这些神经信号输入实时处理系统。系统基于线性回归模型,从低频(LF)和高伽马(HF)神经特征中重建听者所关注语音的时间包络,再将这一重建结果与两段对话各自的时间包络进行比对,以判断听者当前的注意焦点。
一旦系统识别出听者关注的说话者,便会选择性放大该说话者的声音,同时相对压低另一段对话的音量,从而在多说话者环境中实现“定向增强”。
瞄准嘈杂环境下的听力难题
研究人员指出,在嘈杂环境中理解语音仍是听觉神经科学和助听技术面临的主要难题之一。现实场景中,听者往往依赖选择性注意力,将注意力集中在目标说话者身上,同时抑制其他竞争性声音和背景噪音。
现有助听器通常无法判断用户真正想听的对象,往往对环境中所有声音进行无差别放大。这种方式在复杂声场中效果有限,影响实际使用体验和用户接受度,并可能加剧听力障碍者的社交隔离。
“我们开发了一个系统,作为用户的神经延伸,利用大脑在复杂环境中自然过滤声音的能力,动态隔离他们希望听到的特定对话。”哥伦比亚大学研究员 Nima Mesgarani 博士表示。
他称,这项研究尝试突破传统仅对声音整体放大的助听思路,探索能更接近人脑复杂选择性听觉机制的技术方向。
实时算法验证可行性
为实现上述功能,团队开发了实时机器学习算法,用于分析脑电波并识别参与者关注的对话。系统在部署后可快速判断每位听者当前聚焦的语音对象,并据此调整不同说话者的音量比例。
研究显示,无论在实验中由科学家指示受试者关注特定对话,还是由受试者自主选择关注对象,系统均能正常工作,满足多说话者自然对话场景的基本需求。
“为了实现实时效果,系统必须非常快速、准确且稳定,才能让听者获得可接受的聆听体验。”Mesgarani 博士说。
参与试验的志愿者中,有人表示,用大脑直接控制系统的体验“难以置信”,一度怀疑研究人员在后台手动调节音量。也有志愿者提到,身边听力障碍亲友可能从类似技术中获益,有人形容这一体验“像科幻小说”。
从理论走向原型验证
哥伦比亚大学的 Vishal Choudhari 博士表示,团队关注的核心问题是,脑控助听技术能否不再局限于渐进式改良,而是开发出能够在现实环境中实时帮助人们更好听见的原型系统。
“我们首次证明了,一个通过读取大脑信号来选择性增强对话的系统,能够带来清晰的实时益处。”他指出,这一结果标志着脑控助听技术从理论概念迈向实际原型验证。
根据论文信息,该研究题为《实时脑控选择性听觉提升多说话者环境中的语音感知》(Real-time brain-controlled selective auditory enhancement improves speech perception in multi-talker environments),作者为 V. Choudhari 等人,已于 2026 年 5 月 11 日在《自然神经科学》在线发表,论文编号为 doi: 10.1038/s41593-026-02281-5。









