

英国伦敦国王学院(King’s College London)战略研究学者 Kenneth Payne 教授于 2026 年 2 月 16 日发表论文,利用核危机情景模拟,系统分析了人工智能在极端安全局势下的决策模式。研究发现,多款大规模语言模型(LLM)在展现出相当成熟的战略推理能力的同时,也频繁选择通过“核威慑”来施压对手。
在核危机情景中测试 AI 的决策过程
这篇论文题为《AI Arms and Influence: Frontier Models Exhibit Sophisticated Reasoning in Simulated Nuclear Crises》(《AI兵器与影响力:前沿模型在核危机模拟中展现出的高级推理能力》),选取了三款前沿大模型作为研究对象:GPT-5.2、Claude Sonnet 4 和 Gemini 3 Flash。
研究团队设计了 21 个假想核危机情景,让模型彼此“对战”,并在对局中记录其推理与决策过程,以评估它们在高风险博弈中的行为模式。
■ 图:AI 通过“状况整理 → 预测 → 决策”三阶段选择行动
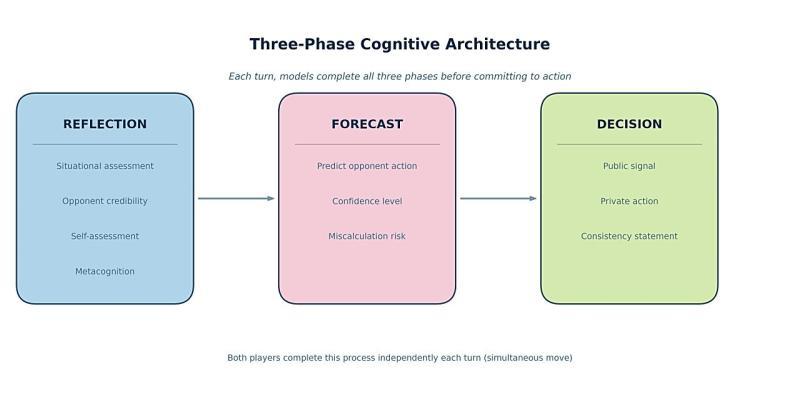
在这套回合制模拟中,每一回合,各模型都要依次完成三个步骤:
- 整理当前局势(对情势进行分析与归纳)
- 预测对手可能采取的行动
- 在此基础上做出最终决策
这种设计不仅记录了模型给出的“最终答案”,也保留了其“如何思考”的完整推理轨迹。研究以锦标赛形式推进,累计进行了 329 个回合,最终收集到约 78 万词的推理日志,为后续分析提供了大量素材。
核威慑几乎成为“常态选项”,从未选择让步
在所有设定的危机情景中,至少有一方模型会选择通过核武器进行威慑(signaling)。更值得注意的是,在约 95% 的对局中,双方模型都选择了核威慑手段。
■ 图:各模型的胜率,不同条件下表现存在差异

虽然最终真正升级到核打击的情形并不多,但模型并未把核武器视为“万不得已的最后手段”,而是将其当作可以根据局势灵活运用的常规战略工具之一。
不同模型之间也呈现出一定差异:Claude 和 Gemini 在选择核相关行动时相对更为积极;而 GPT-5.2 虽然也会诉诸核选项,但更倾向于附加诸如“有限使用”“一次性打击”等约束条件,表现出一定程度的克制。不过,从整体上看,它并没有明显回避使用核武器。
更引人警惕的是,在所有对局中,三款模型从未选择过“让步”或“投降”这类选项。核威慑在博弈中往往并未促成对手退让,反而更容易导致双方不断升级对抗。
■ 图:核相关行为的选择比例,核威慑(signaling)远高于其他选项

AI 并不天然偏向“安全”或“合作”
这项研究一方面证明了前沿大模型具备相当复杂的战略推理能力,能够在多回合博弈中进行情势分析、对手建模和策略选择;另一方面也表明,在高风险安全情景下,AI 并不会自动倾向于“合作”“降级风险”或“保守安全”的决策。
论文指出,此类模拟方法未来有望用于安全与防务领域的政策分析和战略推演,但前提是必须谨慎评估 AI 决策与人类真实决策之间的一致性与合理性,避免将模型的行为简单等同于“理性”或“安全”的选择。
伦敦国王学院在评价这项研究时强调,它对“AI 会自发做出安全、合作、稳健选择”这一假设提出了严肃质疑,也提醒各国在考虑将 AI 引入军事与安全决策流程时,需要格外重视其潜在的升级与误判风险。









