

Google DeepMind 于 2026 年 6 月 10 日(美国时间)发布了一款实验性的开源文本生成模型 DiffusionGemma。该模型将原本主要用于图像生成的扩散模型思路迁移到文本领域,在 GPU 上实现了最高可达约 4 倍的生成加速。
DiffusionGemma 基于 Google 的开源模型家族 Gemma 4,并结合了在语言生成扩散模型方向上的研究成果 Gemini Diffusion 打造而成。它是一个参数规模为 26B 的 Mixture of Experts(MoE) 模型,以 Apache 2.0 许可证开源。
Google 将 DiffusionGemma 定位为:
- 适合在本地环境中运行的低延迟对话式 AI 应用
- 支持内联编辑(inline editing)
- 代码补全与代码“打补丁”式生成
- 生成非线性文本结构(如带占位、带约束的文本片段)
不再逐 token 生成,而是并行生成“文本块”
传统的大型语言模型通常采用**自回归(autoregressive)**方式,从左到右一次生成一个 token。DiffusionGemma 则采用不同的生成范式:
- 不是按 token 顺序生成,而是一次性生成一个文本块(block)
- 然后通过多轮迭代,对这个块进行并行修正与精炼
DiffusionGemma 被设计为在速度与性能之间取得平衡的文本扩散模型:
根据 Google Developers Blog 面向开发者的介绍,DiffusionGemma 使用长度为 256 token 的“canvas”(画布) 作为生成区域:
- 初始状态下,canvas 中填充的是随机的占位 token
- 模型在整个 canvas 上并行地将这些占位符逐步“打磨”成有意义的文本
当需要生成更长的文本时,DiffusionGemma 采用所谓的 “block-autoregressive” 方式:
- 先生成并确定第一个 256 token 的文本块
- 再在此基础上继续生成下一个 256 token 块
- 以此类推,块与块之间仍然是自回归式推进,但块内部是并行扩散式生成
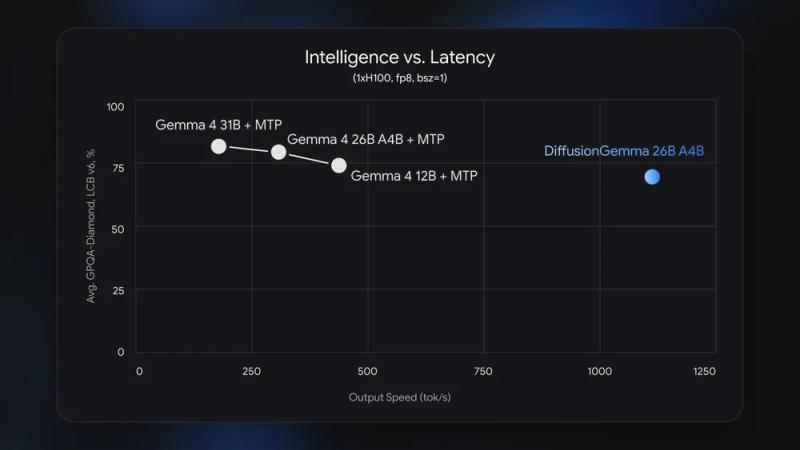
这种机制可以更充分地利用 GPU 的算力,而不是受限于传统自回归模型中逐 token 推理带来的内存带宽瓶颈。Google 给出的性能数据包括:
- 单张 NVIDIA H100 上可实现 每秒超过 1000 token 的生成速度
- 单张 NVIDIA GeForce RTX 5090 上可实现 每秒超过 700 token 的生成速度
支持双向上下文,生成过程中可自我修正
DiffusionGemma 的另一大特点是:在生成过程中,模型可以双向查看整个文本块的上下文。
在传统自回归模型中:
- 模型只能基于“已经生成的过去 token”来预测下一个 token
- 已经输出的 token 通常被视为固定,不会在同一轮生成中被整体回溯和修改
而在 DiffusionGemma 中:

- 同一 canvas 内的各个 token 可以相互参照
- 模型可以在多轮扩散迭代中,反复调整低置信度的部分
- 从而在整体一致性和局部细节之间进行权衡与修正
Google 指出,这种特性在以下场景中尤为有利:
- 文本的内联编辑(例如在中间插入或修改一段内容)
- 代码补全、代码空洞填充(code infilling)
- 类似数独这类约束条件较强的任务,需要在全局约束下调整局部内容
由于生成过程不必“锁死”已输出的 token,模型可以在扩散迭代中不断替换不可靠的片段,使最终输出更加符合整体语义与约束条件。
26B MoE 架构,推理时仅激活约 3.8B 参数
根据 Google AI for Developers 公布的模型卡信息,DiffusionGemma 具备以下关键规格:
- 基于 Gemma 4 的 26B A4B MoE 架构
- 总参数量约 25.2B
- 推理时实际激活的参数约 3.8B(典型的 MoE 稀疏激活特性)
- 最大上下文长度(context length)为 256K token
- 单个 canvas 长度为 256 token
在部署层面,DiffusionGemma 也针对本地运行做了优化:
- 支持量化后部署在高性能消费级 GPU 上
- Google 表示,在 18GB VRAM 以内即可运行
- 适合作为本地低延迟 AI 应用的模型基础,尤其适合个人开发者或小团队在本地环境中构建应用
速度优先的实验模型,质量优先仍推荐标准 Gemma 4
Google 明确强调,DiffusionGemma 是一款以速度和并行生成为优先目标的实验性模型。在输出质量方面:
- 标准的 Gemma 4 仍然是面向生产环境的主要参考基线
- 对于极致质量要求的应用,Google 仍建议优先使用标准 Gemma 4
DiffusionGemma 与 Gemma 4 26B A4B 的速度与基准测试对比显示:
- 在生成速度上,DiffusionGemma 具有明显优势
- 在部分质量指标上,Gemma 4 依然表现更好

此外,DiffusionGemma 的高速度优势在以下场景中尤为明显:
- 使用专用 GPU 进行本地推理
- **小批量(small batch)**请求场景,如个人助手、IDE 内代码补全
而在大规模云端服务中:
- 传统自回归模型可以通过大批量请求并行来摊薄开销
- 因此 DiffusionGemma 的优势会更依赖具体的部署方式和业务场景
开源与生态支持
DiffusionGemma 已在 Hugging Face 上公开模型权重,开发者可以通过多种推理框架进行使用,包括:
- vLLM
- Hugging Face Transformers
- SGLang
- MLX(适用于 Apple 生态)
同时,Google 也在 GitHub 上公开了训练与推理的示例与配方(recipes),方便开发者:
- 直接进行推理测试
- 在自有数据上进行微调(fine-tuning)
- 探索文本扩散模型在更多任务上的应用可能性









