

东京科学大学信息理工学院的冈崎研究室、横田研究室与产业技术综合研究所(产综研)联合研究团队于 2026 年 2 月 20 日发布了两款面向推理任务的大规模语言模型:在 OpenAI 的 GPT-OSS 基础上强化日语与推理能力的「GPT-OSS Swallow」,以及在阿里巴巴 Qwen3 基础上进行同样强化的「Qwen3 Swallow」。
两款模型均以 Apache License 2.0 形式公开权重,可自由用于研究与商用场景,并允许改造与再分发。
基于 GPT-OSS/Qwen3,强化「日语 × 推理」能力
本次公开的模型以现有开源 LLM 为基础,通过再训练与强化学习,重点提升「日语理解与生成能力」以及「思考与推理能力」的平衡表现。
- GPT-OSS Swallow:基于 OpenAI 的 GPT-OSS 构建,提供 20B 与 120B 两个参数规模系列。
- Qwen3 Swallow:基于阿里巴巴的 Qwen3,提供 8B、30B-A3B、32B 等多个尺寸版本。
所有模型均以开放权重形式发布,支持在本地(オンプレミス)环境部署运行,也可在此基础上进行进一步微调与定制。
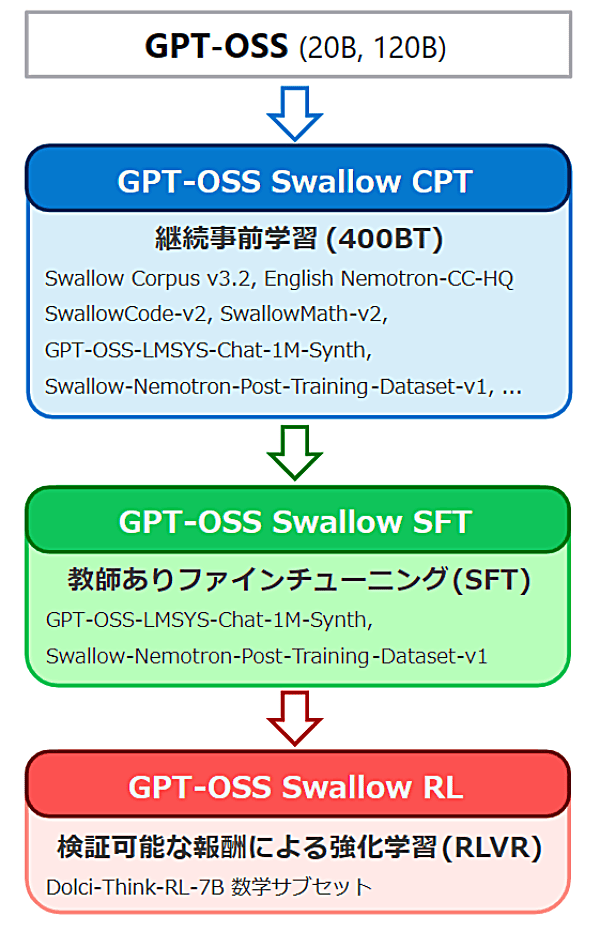
重新设计的 CPT+SFT+强化学习流程
据介绍,冈崎团队对模型的 持续事前学习(CPT)、监督微调(SFT) 与 强化学习 全流程进行了重新设计与构建。
官方页面说明,GPT-OSS Swallow 的训练大致分为以下阶段:
- 持续事前学習(CPT)
- 教師あり学習(SFT)
- 検証可能報酬に基づく強化学習(RL)
通过这一多阶段训练流程,模型在语言理解、指令跟随以及复杂推理方面的能力得到系统性提升。
Qwen3 Swallow 系列同样采用 CPT、SFT 与强化学习相结合的训练策略。研究团队表示,随着训练阶段的推进,模型在各类日语任务上的表现持续提升,验证了该训练流程对日语能力增强的有效性。

同规模以下开源 LLM 中的最高水平表现
根据官方公开的评测结果,GPT-OSS Swallow 20B 与 120B 在与「参数规模相同或更小」的其他开源 LLM 对比时,在 日语任务与英语任务 上均取得了最高水平的综合性能。
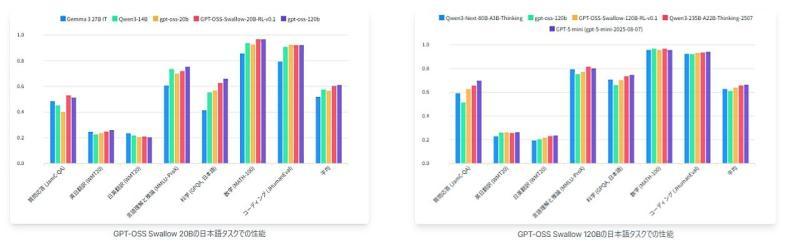
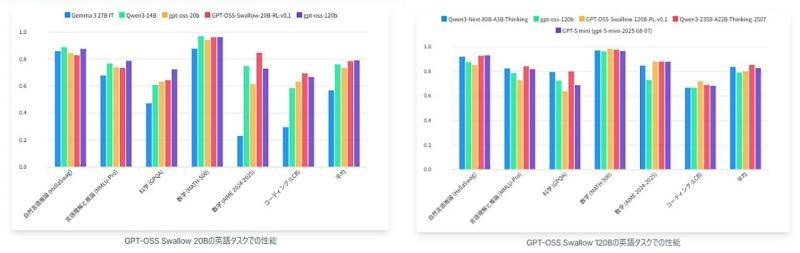
其中,120B 模型在日语 MT-Bench 上的平均得分达到 0.916。官方同时指出,20B 模型在日语相关任务上也取得了较高的平均分,显示出在中等规模参数下的优良性价比。
Qwen3 Swallow 8B 与 32B 也被报告为:在同等或更小参数规模的开源 LLM 中,对日语任务表现出最高水平的性能。
提供量化版本与多种数据集
在 Qwen3 Swallow 系列中,研究团队还提供了 4bit 量化版本,以便在更有限的计算资源环境下部署与运行,降低推理成本。
同时,团队还公开了多种可用于推理型模型训练与研究的数据集,包括:
- Swallow-Nemotron-Post-Training-Dataset-v1
- LMSYS-Chat-1M-Synth(在原始数据基础上,加入由 gpt-oss-120b 生成的推理过程与回答)
- s1-test-time-scaling-synth(面向日语与英语的强化学习数据集)
这些数据集可用于推理型模型的模仿学习(imitation learning)、后训练(post-training)等多种用途,为研究者与开发者提供了可复用的高质量资源。
以 Apache 2.0 开源许可发布
GPT-OSS Swallow 与 Qwen3 Swallow 均采用 Apache License 2.0 授权。这意味着:
- 不仅可用于学术研究,也可直接用于 商用产品与服务;
- 允许对模型进行修改、微调与再分发;
- 在遵守许可条款的前提下,企业与个人均可自由集成与部署。
模型权重与相关数据集已在官方页面及 Hugging Face 等平台上发布,使用者可以根据自身的硬件条件与应用需求下载、部署并进行性能验证或二次开发。









