

中国阿里巴巴旗下的 AI 研究团队通义实验室(Tongyi Lab)正式发布最新大规模语言模型系列「Qwen3.6」,并同步开源其中一款核心模型「Qwen3.6-35B-A3B」。官方强调,该模型采用 Mixture-of-Experts(MoE)结构,在保持高效推理的同时,在 AI 智能体和代码生成等关键场景上取得了领先成绩,整体表现优于 Google 的开源模型「Gemma 4」。
Qwen3.6 系列定位:面向实用场景的升级版本
Qwen3.6 系列是在既有 Qwen3 模型基础上的一次面向实用落地的强化升级。与传统只关注文本生成的模型不同,Qwen3.6 更强调「AI 智能体」场景下的综合任务执行能力,包括工具调用、环境交互、复杂任务拆解与长链路推理等。
通义实验室延续其一贯的开源策略,在 Qwen3.6 系列中继续向开发者开放核心模型,希望通过可实际下载、部署和验证的模型,推动周边生态和应用场景的扩展。
Qwen3.6-35B-A3B:MoE 架构兼顾效率与性能
本次公开的「Qwen3.6-35B-A3B」模型规模约为 350 亿参数,采用 Mixture-of-Experts(MoE)架构。MoE 的核心思路,是在每次推理时只激活部分「专家」子网络,从而在不显著增加计算成本的前提下,提升模型的表达能力和任务适配性。
模型名称中的「A3B」用于标识其激活参数(Active Parameters)的配置方式,即在推理过程中真正参与计算的参数量。通过这种设计,模型在保持较高推理能力的同时,有效控制了计算资源消耗。
相较于同规模的致密(Dense)模型,Qwen3.6-35B-A3B 在效率和可扩展性之间取得了更好的平衡:一方面推理成本更可控,另一方面在多项任务上仍能达到甚至超过同级别 Dense 模型的表现。

基准测试结果:多项指标上超越 Gemma 4
官方公布的基准测试,将 Qwen3.6-35B-A3B 与 Qwen3.5 系列、Gemma 4 系列等模型进行了对比。
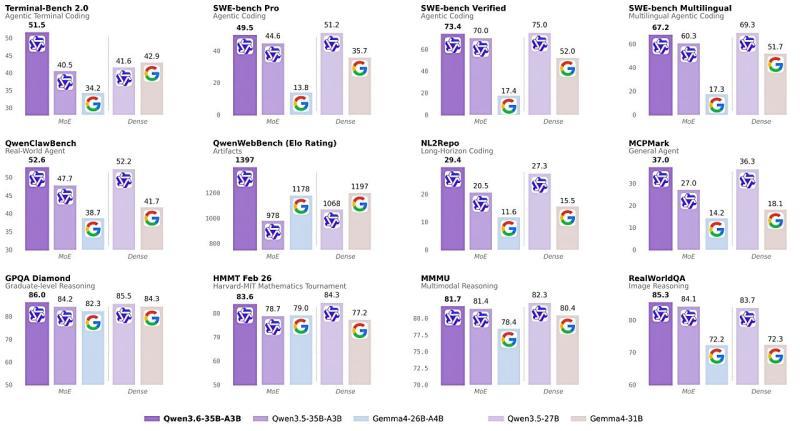
在多项评测指标上,Qwen3.6-35B-A3B 给出了高于 Gemma 4 的分数,尤其在以下方面表现突出:
- SWE-bench Verified(73.4 vs 52.0):在贴近真实开发场景的软件工程与修复任务中,领先幅度明显。
- QwenCodeBench(52.6):在代码生成与代码智能体相关能力上获得高分,显示出较强的编程与问题解决能力。
- Terminal-Bench / WebBench:在命令行操作、网页环境等智能体任务执行能力上具备优势,更适合构建具备实际操作能力的 AI 智能体。
- MMMU / GPQA Diamond:在多模态理解和高难度推理任务上仍保持竞争力,说明模型在通用认知与复杂推理方面也有较好表现。
官方还对比了同规模 Dense 模型的结果,强调在采用 MoE 架构的前提下,Qwen3.6-35B-A3B 依然能够达到甚至超过 Dense 模型的整体性能。
开源与商用许可:开发者可直接集成使用
Qwen3.6-35B-A3B 已在 Hugging Face 平台上公开,开发者可以直接下载并进行本地部署或云端推理。模型采用允许商用的授权条款,可用于各类应用开发与产品集成,包括但不限于:
- 代码助手与自动补全工具
- 面向终端或 Web 环境的 AI 智能体
- 需要复杂推理与工具调用的企业级应用
通过开放核心模型并提供商用友好的许可,通义实验室希望进一步降低企业与开发者采用大模型技术的门槛,加速 AI 在实际业务场景中的落地与迭代。









