

顶级AI编码工具每四次就出错一次
滑铁卢大学的一项最新研究指出,人工智能(AI)在部分基础软件开发任务上依然表现不佳,这对当前广泛用于辅助编程的大型语言模型(LLM)的可靠性提出了质疑。随着LLM在软件开发流程中的应用日益增多,开发者越来越难以保证AI生成结果的准确性、一致性,以及其在大型工程中的可集成性。
这项研究题为《StructEval:评测大型语言模型生成结构化输出能力》,已发表在《机器学习研究汇刊》(Transactions on Machine Learning Research)上,并计划在2026年国际学习表征会议(ICLR 2026)上进行展示。
过去,LLM对软件开发相关提示的回答多以自由形式的自然语言呈现。为改善这一状况,包括 OpenAI、谷歌和 Anthropic 在内的多家AI公司推出了“结构化输出”功能。通过预先定义输出格式(如 JSON、XML 或 Markdown),可以强制模型按照固定结构生成内容,从而便于人类阅读,也更方便被其他软件系统解析和使用。
然而,滑铁卢大学团队构建的新基准测试表明,这项技术距离许多开发者期望的稳定性仍有差距。研究显示,即便是当前最先进的模型,在测试中结构化输出的整体准确率也只有约 75%,而多款开源模型的准确率则徘徊在 65% 左右。
在这项工作中,研究人员对 11 个大型语言模型进行了系统评估,覆盖 18 种结构化输出格式和 44 项具体任务,重点考察模型在遵循结构化规则方面的可靠性。
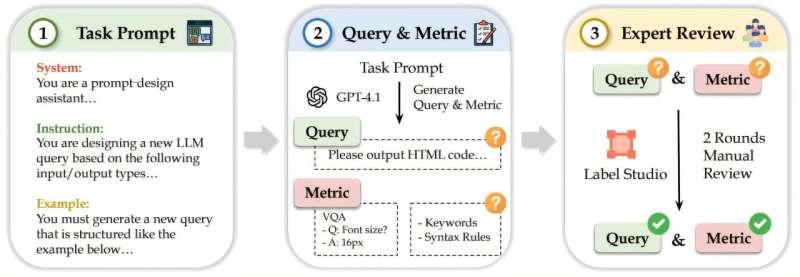
“通过这类研究,我们不仅关注代码在语法层面是否符合既定规则,还要看模型在不同任务下生成的结构化输出是否真正正确,”计算机科学博士生、论文共同第一作者姜东甫表示。
他补充说:“我们发现,这些模型在处理与文本相关的任务时表现还算不错,但一旦涉及图像、视频或网站生成等任务,性能就明显下滑,完成得非常吃力。”
该研究由滑铁卢大学本科生杨佳林发起,助理教授陈文虎参与指导,并联合滑铁卢大学及全球其他机构的 17 位研究人员共同完成。
“最近我们实验室在做很多类似的基准测试项目,”陈文虎介绍道。“在滑铁卢,学生通常从标注员做起,随后逐步负责项目组织并设计自己的基准测试研究。他们不是只在学习中使用AI,而是在亲自构建、研究和评估AI系统。”
尽管LLM的结构化输出技术被视为软件开发领域的一项重要进展,研究团队仍强调,这些系统目前还不足以在完全无人工干预的情况下独立运行。“开发者可以让这些智能体参与工作流程,但仍然需要投入大量人工监督,”姜东甫总结道。









