

一种新的硬件软件协同设计方案显著提升了人工智能在能效和延迟方面的表现,使系统能够对视频流或传感器数据流等连续数据进行实时处理。根据密歇根大学工程学院发表在《自然通讯》上的研究,这一神经形态方法让强大的实时人工智能可以直接在手机、助听器以及自动驾驶车辆摄像头等本地边缘设备上运行。
研究团队首次将复杂状态空间模型——一种前沿的、可替代变换器模型(如 ChatGPT)的新型架构——直接映射到计算存储一体(in-memory computing)硬件上。
“计算存储一体系统具有极高的能效和吞吐量,但其结构较为刚性,不适合传统的卷积网络和变换器网络。在本研究中,我们展示了它们与状态空间模型高度契合。”密歇根大学詹姆斯·R·梅洛工程学教授、论文通讯作者魏璐表示。
他补充道:“状态空间模型中的所有运算都可以通过计算存储一体系统中的器件物理高效实现,这为这些前景广阔的网络提供了高效硬件落地的可能。”
边缘人工智能的效率挑战
在智能手机、可穿戴健康监测设备或自动驾驶车辆等电池供电的边缘设备上直接运行人工智能推理,可以避免数据上传云端,从而提升速度、隐私和整体效率。但现有软硬件体系仍难以高效支撑先进人工智能模型的运行。
在硬件层面,传统架构需要在独立的存储单元和处理单元之间频繁搬运数据,形成高能耗和高延迟的瓶颈。计算存储一体硬件通过在同一位置完成数据存储与计算,能够绕开这一问题,但其结构与大多数主流人工智能模型所依赖的复杂数学运算并不匹配。
在软件层面,变换器模型(如 ChatGPT)在输入序列或对话长度增加时,内存需求急剧上升,长序列推理常常面临内存不足。尖峰神经网络等模型虽然通过仅在新数据到来时激活神经元来提升内存效率,但往往牺牲了精度。研究团队通过软硬件协同设计,针对这两类效率瓶颈提出了统一解决方案。
面向状态空间模型的协同设计
以往高性能状态空间模型通常依赖复数运算,这要求芯片在电路层面分别处理每次计算的实部和虚部,增加了硬件复杂度和能耗。研究人员通过对状态空间模型进行调整,使其仅使用实数运算,从而让每个存储单元可以直接表示一条数据,大幅提升了实现效率。
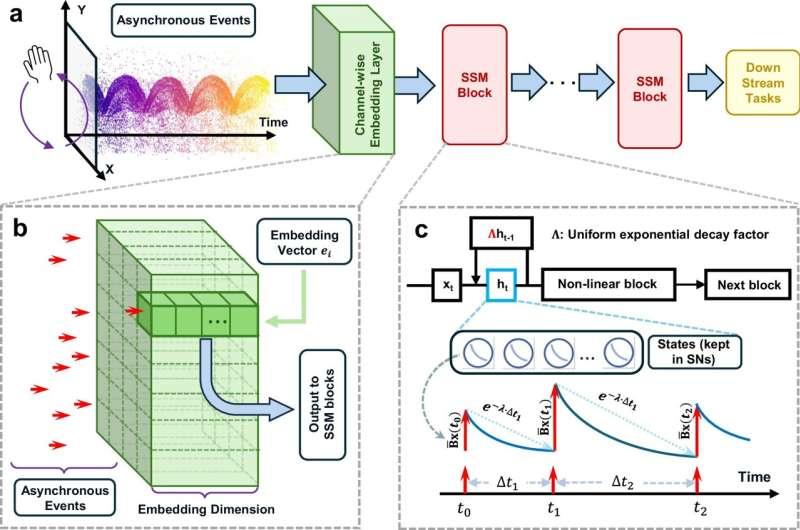
为在保证实时处理的同时避免内存瓶颈,团队为模型的整个模块统一设定了一个固定的衰减率,而不是为每个神经元单独设置不同的衰减率。这个衰减率决定了系统的“短期记忆”长度,即系统在多长时间内保留旧数据、何时“遗忘”以腾出空间存储新信息。
在硬件实现上,状态空间模型被映射到采用标准 65 纳米 CMOS 工艺制造的电阻式随机存取存储器(RRAM)交叉阵列中,具备良好的扩展潜力。交叉阵列本质上是一个晶格结构,在每个交叉点布置忆阻器,用于执行向量-矩阵乘法,从而实现快速、低功耗的计算。
为了让硬件特性与状态空间模型中固定的衰减率相匹配,研究人员制备了不同厚度的氧化钨(WOx)忆阻器。具体做法是,在 400 摄氏度的氧气环境中对钨电极进行 20 秒(形成较薄氧化层)或 80 秒(形成较厚氧化层)的氧化处理。较薄的氧化层对应更快的短期记忆衰减,较厚的氧化层则使衰减更慢。
“状态空间模型在理论上对处理长序列表现出巨大潜力,但在传统硬件上的部署效率非常低。我们的计算存储一体实现,从物理层面重构了状态空间模型的计算方式,使这一方向向高效、硬件原生的人工智能迈出了关键一步,可以在各种场景中落地运行。”密歇根大学电气与计算机工程博士生、论文共同第一作者张晓宇表示。
低延迟、高能效的连续序列处理
在物理实验和模拟基准测试中,这一硬件软件协同设计在处理连续事件序列时展现出高能效表现。RRAM 交叉阵列执行的向量-矩阵乘法结果与理想数学计算仅相差 4.6 位精度。在衰减特性测试中,氧化钨忆阻器的行为与模型预测高度一致,能够满足状态空间模型对记忆衰减的需求。
整体来看,这一新架构实现了实时处理能力,并在延迟和功耗方面明显优于传统数字硬件。
“通常,将复杂算法从理想的软件环境迁移到真实的计算存储一体硬件,会引入噪声并导致性能下降。而在我们的架构中,不仅保持了较高的准确率,还显著降低了能耗。这表明状态空间模型与神经形态硬件在本质上是高度匹配的组合。”密歇根大学电气与计算机工程博士生、论文共同第一作者胡明涛指出。









