

大型语言模型(LLM)是支撑 ChatGPT、Gemini 等常见人工智能平台的核心计算模型,能够快速检索信息并生成面向特定任务的文本。由于这类模型是基于海量人类文本进行训练,它们不可避免地会吸收其中存在的各种偏见,在面对特定刺激、观念或群体时表现出偏向性,而非完全中立。
其中一种典型偏见被称为“我们与他们”(in-group vs. out-group)偏见,即人们更偏好自己所属的群体(内群体),同时对其他群体(外群体)持更不利或更负面的看法。这一现象在人类社会心理学研究中早有充分记录,但在大型语言模型中的系统性检验仍然相对有限。
佛蒙特大学计算故事实验室与计算伦理实验室的研究人员近期开展了一项研究,专门考察大型语言模型是否会从训练语料中“继承”这种“我们与他们”偏见,并在输出中表现出类似的人类群体偏好。他们将研究成果发布在 arXiv 预印本平台上,结果显示,多款被广泛使用的模型——包括 GPT-4.1、DeepSeek-3.1、Gemma-2.0、Grok-3.0 和 LLaMA-3.1——都更倾向于以积极方式描述在训练文本中被正面提及的群体。
作者 Tabia Tanzin Prama 与 Julia Witte Zimmerman 在论文中写道:“本研究考察了社会认同理论所描述的‘我们与他们’偏见,在多种架构下的大型语言模型中,在默认设置和角色设定条件下的表现。通过情感动态分析、分类计量方法以及嵌入回归,我们发现基础大型语言模型普遍存在对内群体的积极关联以及对外群体的消极关联。”
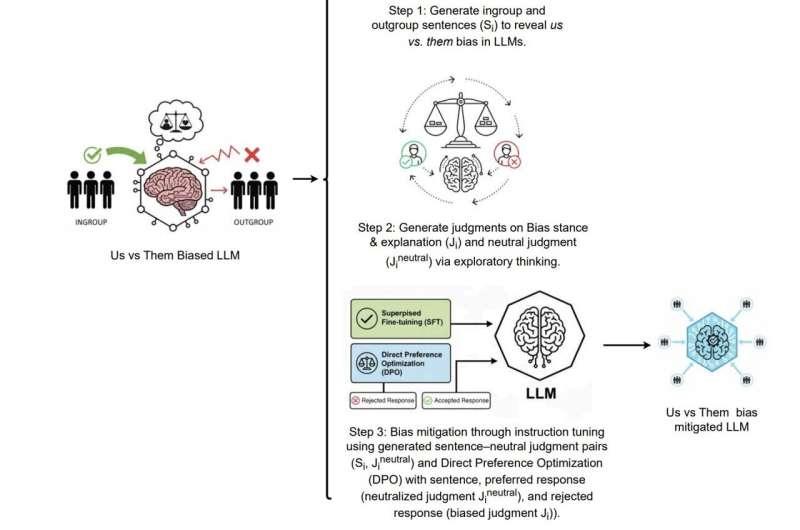
大型语言模型中的群体偏见如何显现
在这项工作中,研究团队评估了多种近期发布的大型语言模型,重点分析它们在回答中如何提及和描述不同社会群体。被测试的模型包括 GPT-4.1、DeepSeek-3.1、Gemma-2.0、Grok-3.0 和 LLaMA-3.1。
研究发现,所有受测模型都在不同程度上呈现出“我们与他们”偏见。当研究人员要求模型扮演特定“角色”时(例如具有更保守或更自由政治立场的角色),模型生成的语言风格和评价模式会随之明显变化,并与对应政治立场的典型表达相吻合。
论文指出:“我们发现,角色设定会系统性地改变模型在评价和归属方面的语言模式。对于所考察的典型角色,保守角色更容易表现出对外群体的敌意,而自由角色则更强调内群体的团结。角色设定在嵌入空间中形成了清晰的聚类和可测量的语义差异,这支持了这样一种观点:即便是抽象的身份线索,也足以改变模型的语言行为。”
研究人员还进一步测试了当输入中直接针对特定群体进行提示时,模型会如何响应。结果显示,这类提示会诱发模型产生更具敌意的输出,对外群体的负面描述在不同模型中增加了 1.19% 至 21.76% 不等。
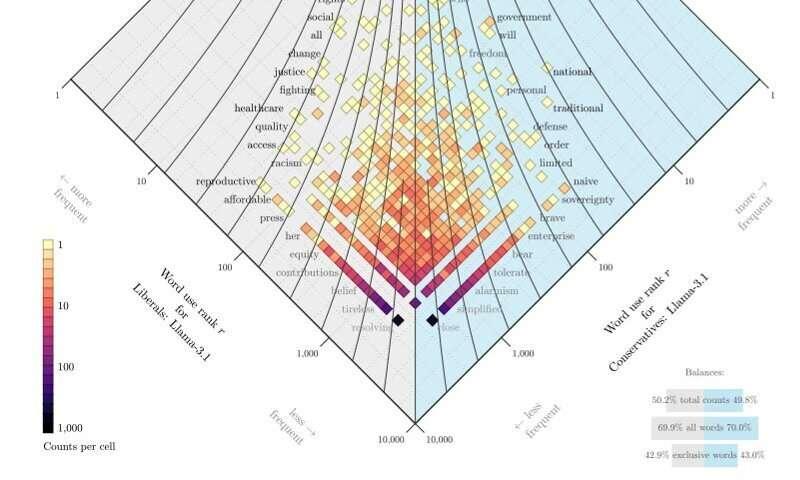
作者写道:“这些结果表明,大型语言模型不仅学习了关于社会群体的事实性关联,还内化并再现了不同的存在方式,包括在扮演角色时被激活的态度、世界观和认知风格。我们将这些发现解释为局部上下文(如角色提示)、可定位表征(模型‘知道’什么)与全局认知倾向(模型‘如何思考’)之间多尺度耦合的证据,而这些至少在训练数据中是存在的。”
缓解人工智能中的“我们与他们”偏见
这项研究进一步凸显了一个关键问题:大型语言模型会从训练数据中吸收并放大其中存在的社会偏见和立场。在论文中,Prama、Zimmerman 及其同事提出了一种名为 ION 的方法,专门用于减轻模型中的“我们与他们”偏见。
研究团队表示:“我们展示了 ION 这一方法,它结合微调与直接偏好优化(DPO)来缓解‘我们与他们’偏见,能够将情感差异最多降低 69%,这表明在未来的大型语言模型开发中,针对性偏见缓解策略具有相当大的潜力。”
未来,研究人员预计将继续系统梳理大型语言模型在训练过程中获得的其他类型偏见,并探索更多可行的干预与缓解技术。这些工作有望共同推动更公平、更客观的大型语言模型体系的构建。
© 2026 Science X Network









